
🔮 Feel the AGI yet?
Initial reflections on GPT-5
OpenAI unveiled the much-delayed GPT-5 yesterday. I’m still away on a family holiday, but I wanted to share my early impressions here. They’ll evolve as we push the model.
Does the new release make us ‘feel the AGI’?
GPT-5 outperforms GPT-4 by a wide margin but shows only slight gains over o3, Anthropic’s Claude 4, and xAI’s Grok 4 on many tasks. In hands-on use, though, it behaves more agentically –taking initiative and stitching steps together more capably.
I’d characterize the new release as evolutionary rather than revolutionary. But we might still be surprised as new patterns emerge.
In today’s post, we’ll cover:
GPT-5 and the rise of personal micro-software
Hallucinations, factual accuracy and groundedness
What this release signals about OpenAI’s strategy and the competitive field
Thoughts on GPT-5 & AGI
But first, how GPT-5 came to be
To train the new model, OpenAI used o3 to generate training data, as Sebastien Bubeck explained:
We used OpenAI’s o3 to craft a high-quality synthetic curriculum to teach GPT-5 complex topics in a way that the raw web simply never could.
This could be repeated. Using the previous generation to create synthetic training data for the next. So far, there is no hard limit to how many times this can be done. As long as each new teacher is stronger than the last and synthetic data is added rather than replacing the original, research suggests each generation of models should improve. Whether it can solve all remaining problems, like memory, hallucinations and context-management, remains up in the air.
An era of personal micro-software?
The AGI vibe comes from the agentic UX. It feels like the AI is doing things for you, rather than you telling it what to do. You give it a direction, and it’ll make most of the choices. This further lowers the barrier to creating the tools you need, without code or specialized knowledge. Take the Korean learning app my team built, inspired by the OpenAI demo: it asks for your preferences, then instantly produces a working flash-card app with real audio and a matching game. It’s the kind of personalized micro-software that anyone could soon create.
And personalized micro-software could be a really big deal. In just a couple of prompts, Nathan Warren created a budgeting app personalized to his bank and preferred budgeting method.
I spoke about this recently with GitHub’s CEO Thomas Dohmke. He recounted Manus AI’s founders using their agent to spin up a single-purpose micro-app to scout Tokyo office space. GPT-5 could put that capability in everyone’s hands.
GPT-5 approaches tasks in a completely different way to previous systems. It pauses to think, uses a tool, reflects – perhaps tries a different tool – then acts again. It reasons through the process. Claude 4, by contrast, tends to move straight through chaining tool calls together without that intermediate reflection.
As Ben Hylak notes:
GPT-5 doesn’t just use tools. It thinks with them. It builds with them.

Why choose?
Another major upgrade is that you no longer have to agonize over choosing models or micromanaging parts of the system to get the best output. GPT-5 decides how to answer, how much reasoning to do and which tools to use. This kind of model-routing is already increasingly common in enterprises running fleets of LLMs. It significantly reduces cognitive load by shifting those decision to the system.
You no longer need to fuss over every detail in the prompt, either. You can give vague instructions and the system will figure out the details, often delivering more than you asked for. In the Korean app example, it added features I didn’t ask for nor would have thought of. Ethan Mollick noticed the same thing:
I used to prompt AI carefully… now I can just gesture vaguely at what I want.
While you can still steer the AI, OpenAI’s design makes deep, critical engagement feel optional – a potentially harmful direction. My son tested GPT-5 with a math problem. It got the right answer, as did GPT-4o and Gemini Pro 2.5 – but it hid its working. That’s not a habit to normalize. LLMs are more useful when they show their reasoning, so you can learn from them or check their work.
An MIT Media Lab pre-print found that participants who wrote essays with ChatGPT showed lower EEG activity in regions tied to executive control and produced more formulaic text. The default behavior might drift toward ever more uncritical prompting. We reflected on this recently, learning from our own mistakes.
A tighter grip on reality
For an agent to track and execute its plan, it must reason across thousands of words. GPT-5 leads by seven percentage points on a benchmark tracking this performance.1 Just as important, GPT-5 hallucinates roughly 6-8x less often than OpenAI o3, depending on the benchmark.2
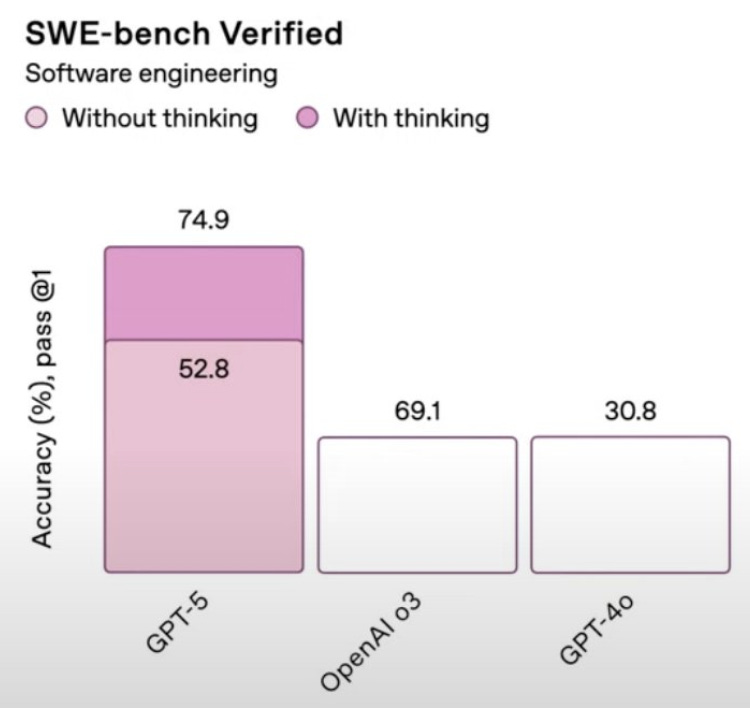
However, new failure modes always have a way of appearing. A few moments in yesterday’s presentation rattled the confidence. One slide committed a glaring chart crime (apparently 52.8 > 69.1 = 30.8),3 and one workflow demo had GPT-5 return an incorrect theory on how plane wings generate lift. No doubt, it will not always cooperate. In our first attempt to build a web app with GPT-5, it kept insisting that we had to write the code ourselves. The issues we are used to will remain, but I expect to encounter them less often.
The benchmark we’re paying most attention to is METR’s ‘Measuring AI Ability to Complete Long Tasks’ benchmark. GPT-5 can now complete software tasks averaging 2 hours and 17 minutes in length with a 50% completion rate, up from 1 hour and 30 minutes for o3. But if you want an 80% completion rate, the maximum task length drops to tasks of about 25 minutes — only slightly longer than o3 and Claude Opus 4, which average around 20 minutes.

In other words, the ceiling has lifted more than the floor. If we want agents to take on longer, more complex tasks end-to-end, that floor will need to rise quickly (see EV#534 on this).
Still, the trajectory is promising. GPT-5 can stitch together small, vibe-coded software with striking accuracy and, dare I say, creativity. Watching it succeed at tasks it once fumbled is genuinely exciting.
Market share by giveaway
And that delight will soon reach everyone. About 700 million people use ChatGPT weekly, and all of them now have access to GPT-5. You don’t have to pay. There are rate limits, of course, but the offer feels extremely generous. It also means most consumers will be embedded in their models, rather than their rivals. This will entrench OpenAI’s consumer lead.
On the developer side, the API is competitively priced and beats other foundational providers. Claude 4 Opus, the closest rival in developer tasks, matches GPT-5 yet costs roughly 10x more. That’s a concern for Anthropic, given that 60% of its revenue comes from API products, half of which depend on developer tools like Cursor and GitHub Copilot. Even Cursor’s CEO says GPT-5 is the smartest coding assistant he has tested. Not good news for Anthropic.
More intriguing, from a strategy angle, is that OpenAI launched GPT-5 just days after releasing two frontier-pushing open-weight models.
