Azeem's commentary: Waiting for GPT-4
On the generative wave, Part 2
If you missed Part 1 of the On the Generative Wave series, read it here.
It’s been 29 months since OpenAI launched GPT-2, its large-language model which demonstrated the power of transformers-based neural networks. GPT-2 impressed with the quality of its natural text generation. Its successor GPT-3, a bigger, more complex model, delivered even more powerful results.
Since GPT-3 was released in 2020, we have witnessed a wave of new innovations and products built on it and similar models. It isn’t just about feeding a model a text prompt and having it spew out lots of plausible-sounding (but not necessarily true) copy. We’re witnessing the same prompt-based approach to images, movies and more.
Now, rumours are swirling about GPT-4, OpenAI’s newest model due in the next three months. Even the popular tabloid British newspaper, The Sun, has an article on it. 1
What should we expect?
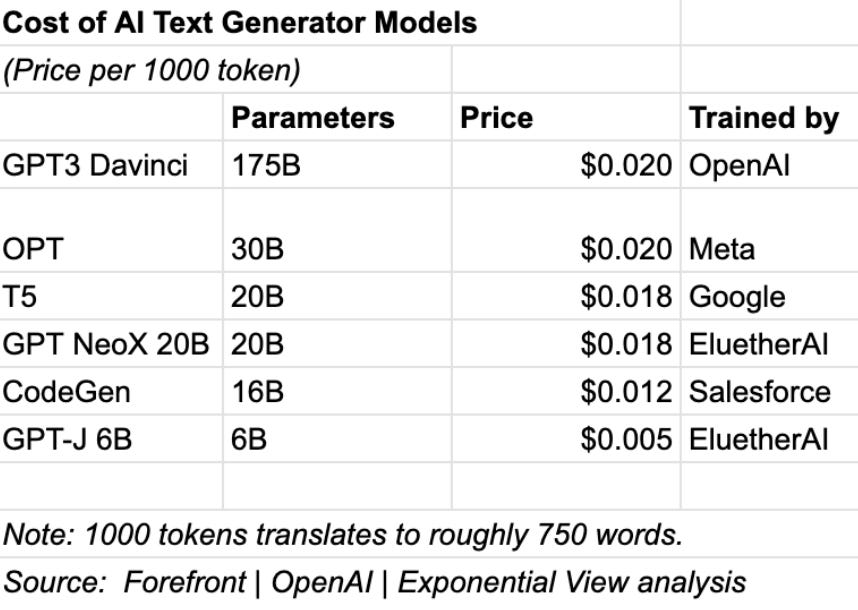
As The Sun’s article points out, GPT-4 may buck the trend for every larger and larger models. Back in 1998 Yann LeCun’s breakthrough neural network, LeNet, sported 60,000 parameters (a measure of the complexity of the neural machine to do useful things). Twenty years later, OpenAI’s first version of GPT had 110 million parameters. GPT-2 has 1.75bn and GPT-3, now two years old, has 175 billion. More parameters mean better results. State of the art multi-modal networks, which can go from text-to-image to text-to-text or other combinations, are even more complex. The biggest are approaching 10 trillion parameters.
Earlier this year, OpenAI’s boss Sam Altman said that GPT-4 would not be much more complex than GPT-3 nor would it be multi-modal, sticking to text-only. This might disappoint those who hope that the next version of GPT-4 would be all singing and dancing. That OpenAI would prove you can just scale neural networks towards the complexity of the brain’s connectome. That this scale would produce logical reasoning, temporal understanding, real-world abilities and an easy insouciance at dealing with text, video, images and audio.
I’m going to take Altman’s remarks earlier this year at face value. GPT-4 will not be much larger than its predecessor and will only deal with text. (But I am cautious: Altman teased us with a recent tweet, embedded below.)

What I’m sure we’ll get
We’ll get a text generator that beats current state-of-the-art benchmarks. There would literally be no point doing this if GPT-4 didn’t achieve things that extant services can already do. What could this mean? Even more realistic text output in different scenarios, from dialogue to long-form? Across different styles?
On the price front: it would make sense for GPT-4 to cost less than GPT-3 and other services. The price for generated text has been declining rapidly. It’s already as low as half a cent for about 700 words of output.