
🔮 The age of reason(ing models)
Learning, agents and the $ trillion opportunity
In advanced economies, knowledge workers represent roughly a quarter of the labor force and generate trillions in output. Even modest gains in their productivity, powered by advancements in AI, could trigger enormous economic returns.
But those gains won’t simply come from making models bigger. It’s about teaching these models to reason systematically—an approach made possible by reinforcement learning. And it’s already happening, big time.
Last week, Alibaba unveiled QwQ-32B, a model punching well above its weight. Despite being significantly smaller than competitors like DeepSeek-R1, early benchmarks show comparable performance—the latest evidence that reinforcement learning is changing the AI landscape.
Even the Qwen team noted, “Scaling RL has the potential to enhance model performance beyond conventional pre-training and post-training methods.”
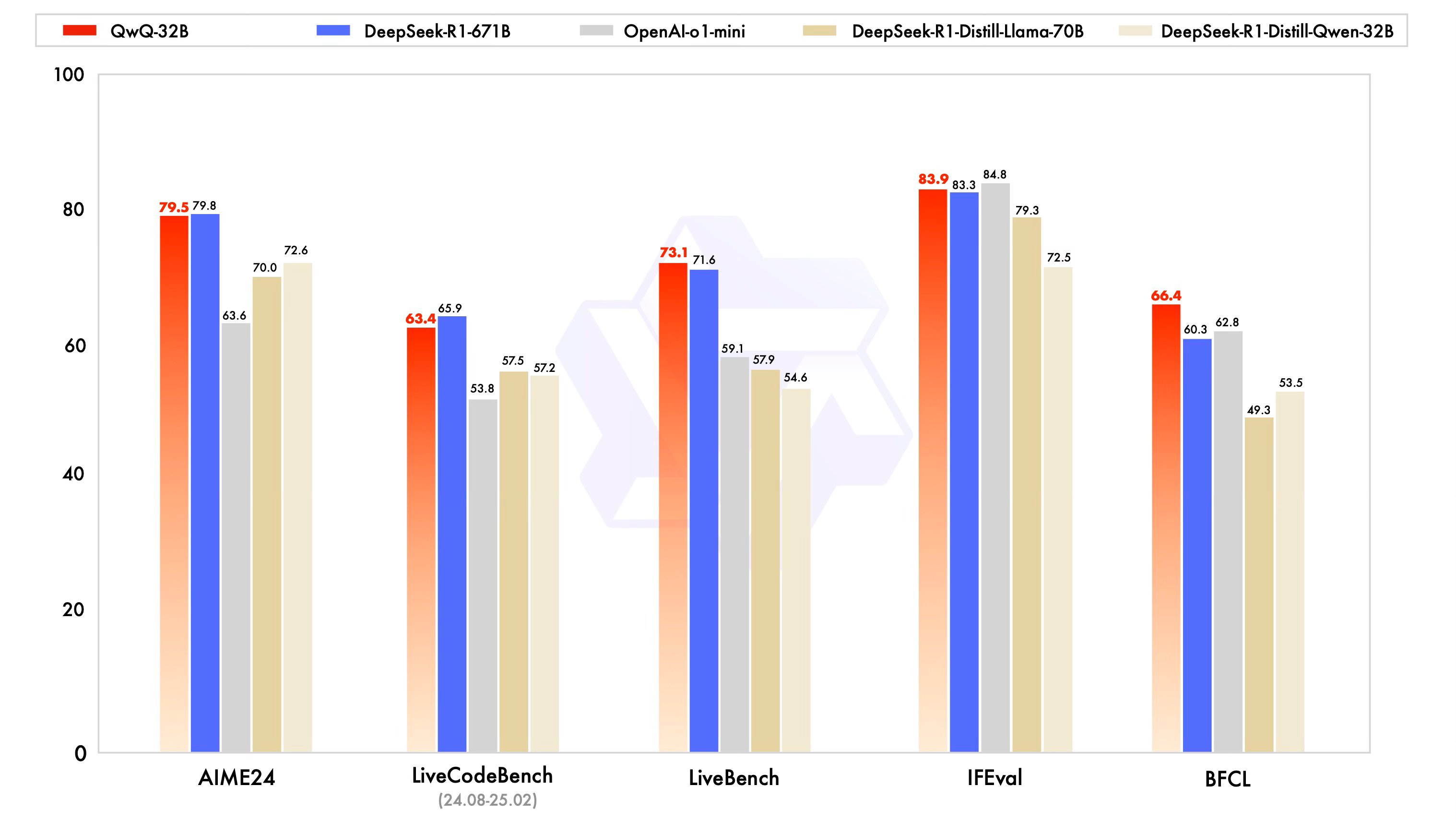
This marks a crucial turning point. We’re no longer talking about AI systems parroting patterns from massive datasets. Instead, we’re witnessing the rise of models capable of structured, methodical reasoning—a shift that could redefine knowledge work and directly impact your role, your industry, and even your future.
Here’s how we got here.
Move 37
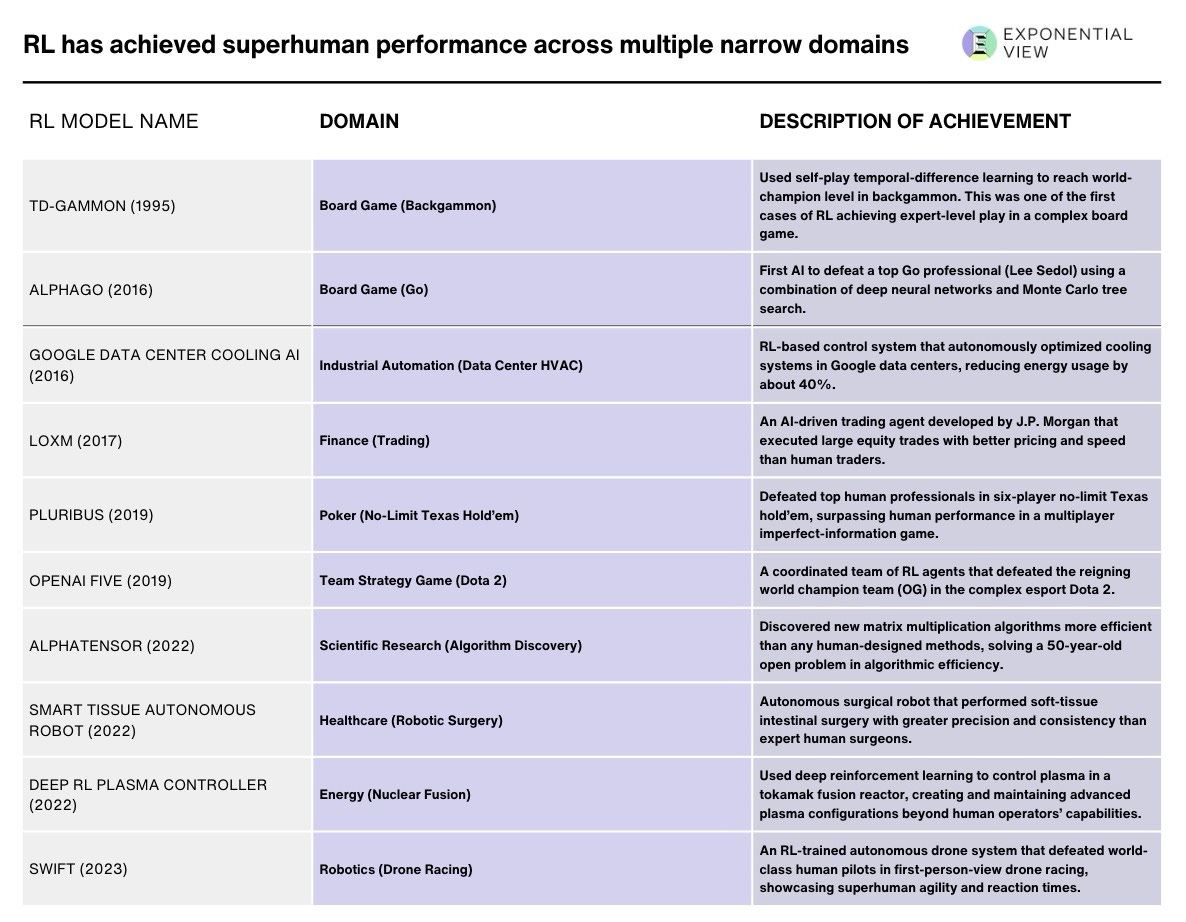
In the spring of 2016, the Go community was stunned. AlphaGo’s Move 37 in its match against world champion Lee Sedol initially appeared to be a blunder. Even Sedol left the room, rattled by the machine’s improbable move.
At first, many observers wrote off AlphaGo’s Move 37 as an odd mistake. Yet once the match ended, experts realized that centuries of human strategy had just been outmaneuvered by a distinctly machine-led perspective.
The secret behind this move was reinforcement learning.
Instead of relying on pre-coded strategies, RL systems learn optimal play through trial and error: they earn rewards for successful moves and penalties for poor ones. Over countless iterations, AlphaGo refined its gameplay well beyond conventional patterns.
This moment marked the shift from pattern matching to systematic problem-solving. Until then, many had assumed computers were just replaying memorized moves. But here was AlphaGo inventing a move grandmasters never anticipated—crossing a threshold from rote calculation to meaningful innovation.

The drama seen on the Go board is now unfolding in the realm of human language. Reinforcement learning excelled in precise, well-defined environments—like board games—where outcomes are clear-cut: did the AI improve the board position? Did it win or lose? Those simple yes/no signals propelled AlphaGo to superhuman levels of play.
Outside of games, however, RL faced obstacles. Many real-world tasks lack clean “victory conditions,” so it was harder to apply the same reward-based methods.
Meanwhile, by 2019, OpenAI’s GPT-2 drew massive attention with its ability to produce coherent text. Other large language models quickly followed and suddenly RL took a backseat as researchers rushed to make the most of the power of large-scale text prediction.
But RL never disappeared—it was just regrouping.
Now, it has returned to the spotlight to combine language generation with the rigorous, step-by-step logic that made Move 37 possible in Go.
RL be back

With the release of o1-preview at the end of last year, OpenAI introduced “reasoning models” that “think” before answering a user’s query.
This thinking process was trained using RL which improved the model’s performance on STEM and coding tasks, problem-solving that require multi-step logic rather than simple word prediction.
A good example of RL’s strengths is obvious from a coding challenge set by Andrej Karpathy. He asked a model for a Settlers of Catan–style hex grid on a webpage, with each tile numbered and the entire grid size adjustable via a slider. In other words, a single HTML page that can dynamically generate and label an ever-changing hexagonal layout.
An RL-trained reasoning model systematically breaks the request into smaller tasks:
Define the problem (creating an interactive hex-grid webpage)
Plan the technical approach (selecting appropriate tools like HTML, CSS, JavaScript and SVG)
Solve geometric and numbering logic (calculating coordinates, hex shapes, and numbering the tiles)
Implement interactivity and finalize the solution (adding a slider for adjusting board size, centring the grid, and producing usable code)
By handling each sub-problem in sequence, the RL-based model can produce a working solution that genuinely meets the prompt.

In contrast, a standard large language model like GPT-4 might produce code that looks promising but doesn’t fully solve the geometry or interaction details.

It’s not just for coding either. OpenAI’s Deep research also employed RL training to be able to conduct multi-step investigations instead of one-shot answers. It’s not perfect, but it offers an early idea of RL’s potential to make AI perform economically-significant tasks.
From language to reasoning
Reinforcement learning seemed a natural way to improve large language models, yet applying it to language was far from straightforward. Models like GPT-3 learn to predict the next word by identifying patterns in massive amounts of text—in GPT-3’s case, about 200 billion words.
But RL hinges on accumulating rewards, such as scoring a point in a video game or capturing a piece in chess, and it was unclear how to define a similar “reward” for language. In a game of chess, the payoff is obvious when a piece is taken. But what is the correct answer for completing the sentence “I love it when it….”?
Initially, RL was used to fine-tune LLMs with human feedback, ensuring they responded politely and helpfully. This was pioneered by Christiano et al. (2017) and later popularised by OpenAI’s InstructGPT. In essence, reinforcement learning from human feedback (RLHF) made models more user-friendly rather than sharpening their underlying reasoning skills.
That began to change when researchers started applying RL to tasks with clear success criteria—such as writing bug-free code or solving multi-step math puzzles. Here, language outputs can be measured objectively: a theorem can be proven or disproven by a logic checker, and code either passes its unit tests or fails. With reliable ways to check correctness, models can be rewarded (or penalised) based on how accurately they solve the problem, rather than on how “nice” they sound.
Over the past six months, AI labs including OpenAI, Google, Anthropic, xAI and leading Chinese research teams have introduced advanced models that leverage RL for what is called chain-of-thought reasoning. These systems begin with a powerful language model and then use RL to refine their ability to think step-by-step. Complex tasks—coding hex grids, solving physics equations—are broken into logical steps, each of which is tested for accuracy or consistency, often via automated verifiers or test suites. Correct steps are rewarded, gradually improving the model’s reasoning process.

A good illustration of this method is the DeepSeek-R1 reasoning model. According to their research paper, DeepSeek first created a precursor model, R1-Zero, which used RL exclusively to attempt various tasks. This produced an extensive dataset—over 600,000 reasoning example.1 After filtering and refining this data, DeepSeek trained the final R1 model, blending robust problem-solving skills with coherent language generation. The resulting reasoning model doesn’t just predict the next word; it learns to systematically think through, plan and revise its approach to a problem. This way it can tackle tasks that would flummox traditional LLMs.

This training process sometimes leads to surprisingly human-like leaps. During DeepSeek-R1-Zero development, logs showed a moment when the model paused mid-thought, noticed a contradiction and revised its approach—without human direction to “stop, reflect, and backtrack.”
R1-Zero spontaneously developed self-correction. Over repeated trials, the system learned to double-check its logic, much like someone spotting a misplaced puzzle piece. It was as though the model discovered how to assess its own reasoning.

Educational theorists have long emphasised trial-and-error plus reflective feedback. Jean Piaget’s theory of cognitive development showed how new information forces children to adapt. R1-Zero’s cycle of propose–reward–revise closely echoed these ideas, hinting at metacognition—though it lacks human-like consciousness. Its “thoughts” are digital tokens, its “reward” a numeric measure—yet the parallels to human learning are there.

Similarly, OpenAI’s o3 gained attention because it no longer needed pre-programmed shortcuts. Earlier models, like o1-ioi, relied on carefully designed rules to solve coding tasks, but o3 took a different approach. By expanding its reinforcement learning stage, it learned how to independently generate, test and improve its solutions. In fact, o3 became skilled enough to perform detailed checks on its solutions, sometimes even testing multiple options to see which worked best. It’s now so capable that it ranks among the top 200 competitors on CodeForces, a prestigious competitive programming site.

But what if we take it further? Imagine your task involves finding an obscure spreadsheet buried somewhere in your company’s Google Drive, running an analysis on it and sending the insights to senior management.
Reasoning models already do well at breaking down problems and planning logical steps—but what if we gave them tools? What if we turned them into fully autonomous agents capable of independently searching, analysing, and delivering results?
Well, it turns out — you can use RL to make functioning agents.
Unlocking agents
Consider OpenAI’s Deep research. Unlike earlier AI models that required explicit instructions or carefully handcrafted rules, Deep research was trained using end-to-end reinforcement learning. It autonomously crafts research strategies, dynamically adapts based on real-time search results —much like a human analyst exploring uncharted territory.
Josh Tobin of OpenAI describes this as a critical turning point:
If you’re able to optimize directly for the outcome you’re looking for, the results are going to be much, much better than if you try to glue together models not optimized end-to-end.

Tobin emphasizes that reinforcement learning is likely essential. The model independently plans, executes and refines its approach without scripted directions or frequent human oversight.
Imagine AI agents independently backtesting investment strategies in finance, verifying arguments against legal precedents, refining medical diagnoses through simulations, or automating complex engineering validations. In Josh Tobin’s words
There’s nothing stopping that recipe from scaling to increasingly complex tasks… It will surprise people.
Agents empowered with autonomous reasoning and multi-step planning could reshape entire industries—fundamentally, not incrementally.
The economic implications
There is an economic earthquake waiting to happen. GPT-4o managed just 30% on SWE Bench’s real-world coding tasks, while Claude 3.7 Sonnet — a reasoning model —achieved 70%. That 40-point gap is already reflected on the bleeding edge of our economy: 25% of the latest Y Combinator startups generate 95% of their code with AI.
Why? Because AI-powered development leads to blazing-fast minimum viable products. Even the now-primitive 2023-era GitHub Copilot (think “Windows 95” of coding AIs) helped developers finish tasks 50% faster. I can only guess how much faster it is now with products like Cursor and Windsurf —and the number would be so wild I wouldn’t dare write it down without peer-reviewed evidence.
Software engineering might be the most obvious early frontier. Developers sit right next to AI’s beating heart—but other analytical fields are following closely behind.
