
🚀 Can AI escape Google’s gravity well?
The empire just struck back
Some two and a half years ago, Google faced a GPT tidal wave. Sundar Pichai may (or may not) have declared a “code red.” This week, words gave way to a physics lesson in vertical integration.

When massive objects warp spacetime, smaller things will either get captured by the gravity well or achieve escape velocity. Google is adding enormous mass to the AI field: $93 billion in capex, custom silicon, vertical integration top to bottom, coupled with the breakthroughs from the research team at Google DeepMind.
Does that mean game over for competitors? Well only if intelligence is a monolithic mass, one dimension where the biggest model always wins. But that “God Model” fallacy, the notion that intelligence is monolithic, doesn’t sit with my intuitions, as I have written previously. Recent research from Epoch AI concurs, suggesting intelligence is more multifaceted. If that’s true, Google’s gravity well has a floor but not a ceiling. It’s tough to escape by matching their mass. You escape by achieving different densities in other dimensions.
Keep that frame in mind as we look at what Google just shipped this week.
Inside the launch
This week Google released a new flagship LLM, Gemini 3, which includes an advanced thinking capability called DeepThink. Accompanying the launch was a remarkable new image generator called Nano Banana 3 and some developer tools.
I’ve been running Gemini 3 through my usual battery of tests in the run-up to this week’s launch. It’s a noticeable upgrade on Gemini 2.5 – sharper reasoning and a real jump in dealing with complex, theoretical questions. It’s also a concise communicator.
Compared to GPT-5, differences showed up quickly. GPT-5 tends to pile on layers of complexity; Gemini 3 gets to the point. That clarity compounds over hundreds of queries. I now default about a third of my prompts to Gemini 3. I’ve also moved a high‑stakes multi‑agent “council of elders” workflow, where several different prompts challenge and critique analyses, from GPT‑5 to Gemini 3. In that workflow GPT-5 worked noticeably better than Claude 4.5; Gemini 3 Pro is the best of the lot.
Model choice isn’t about novelty-chasing. You’re recalibrating the tone of a colleague you consult dozens of times each day. And for those who need numbers, Gemini 3 Pro tops Anthropic and OpenAI across a wide range of benchmarks.
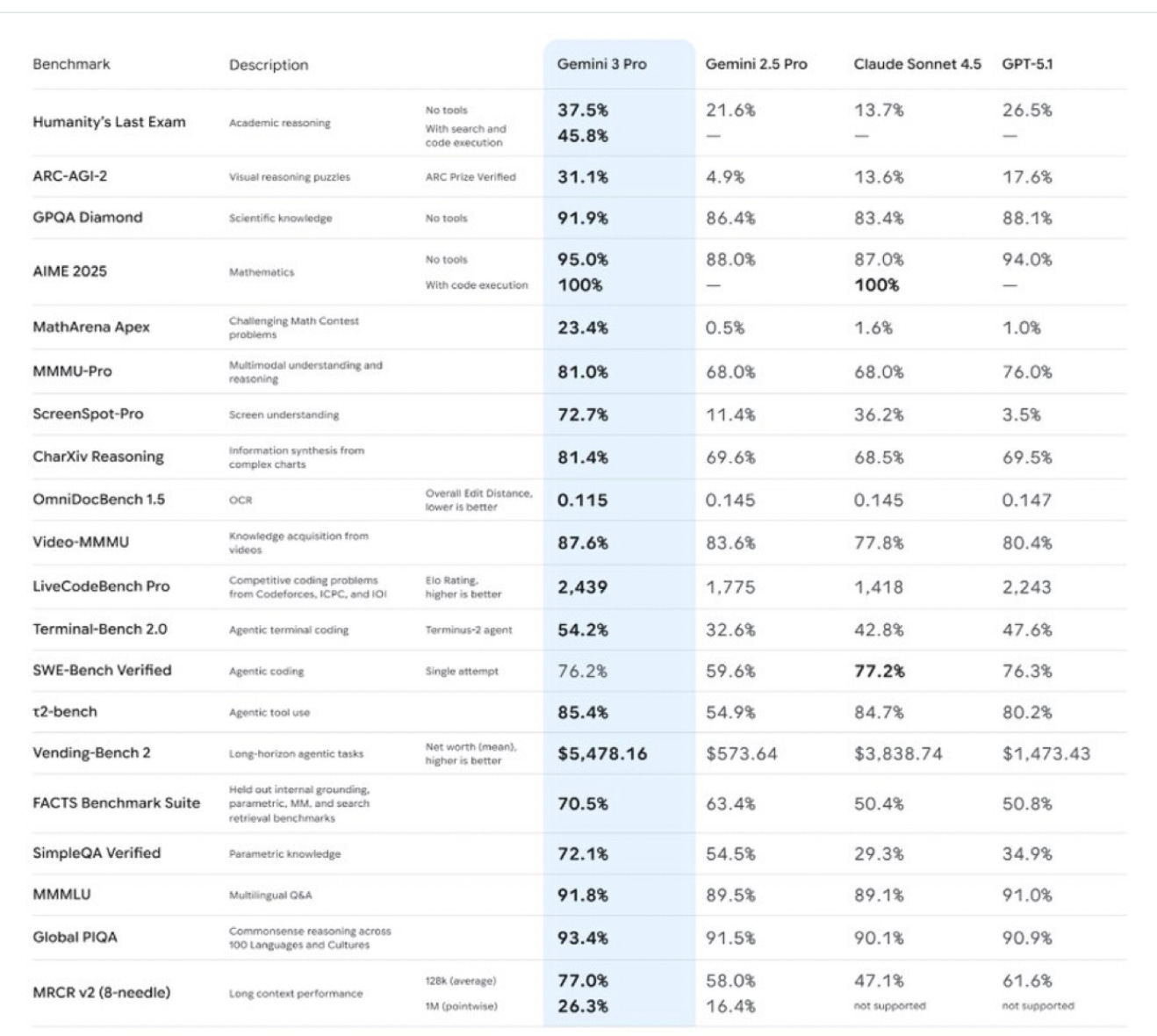
If we just focused on Alphabet’s technical milestones, we’d miss half the picture. The unsung hero here is the firm’s deep infrastructure.
Markets are jittery about AI spend and the bubble chatter. It’s the tension of the “exponential gap”, linear financing pulled by exponential tech. Even Sundar Pichai has flagged elements of “irrationality.”
Alphabet raised its capex guidance three times this year. It now expects $91-93 billion of capital expenditure in 2025, up from about $52.5 billion in 2024, and has already signalled a “significant increase” again in 2026.
So far, that splurge has not forced a retreat from the financial cosseting that Alphabet offers its investors. The firm authorised a $70 billion buyback in 2025, spent roughly $62 billion on repurchases and $7 billion on dividends in 2024, and is still retiring around $10-12 billion of stock a quarter while paying a $0.21 quarterly dividend.
The vast bulk of the capex is going into technical infrastructure, servers, custom tensor processing units and the data centres and networks that house them, with recent cycles funding the shift to the new Ironwood TPUs and the AI Hypercomputer fabric that ties them together. Nvidia will still get a slice. Google Cloud continues to roll out high‑end Hopper‑ and Blackwell‑class GPU instances, and the Gemini and Gemma families are being optimised to run on Nvidia hardware for customers who want them.
But the core Gemini stack – training and Google’s own first‑party serving – now runs almost entirely on its in‑house TPUs. And those Ironwoods are impressive. They are comparable to Nvidia’s Blackwell B200 chips, delivering similar amounts of raw processing (42 exaFLOPs FP8 for Ironwood) and the same 192GB of HBM3e memory. But Google’s chips only need to be good at one thing: “Google-style” house models, massive LLMs with Mixture-of-Experts inference, for high-throughput serving. And so Ironwood promises lower cost per token and latency for Google services.
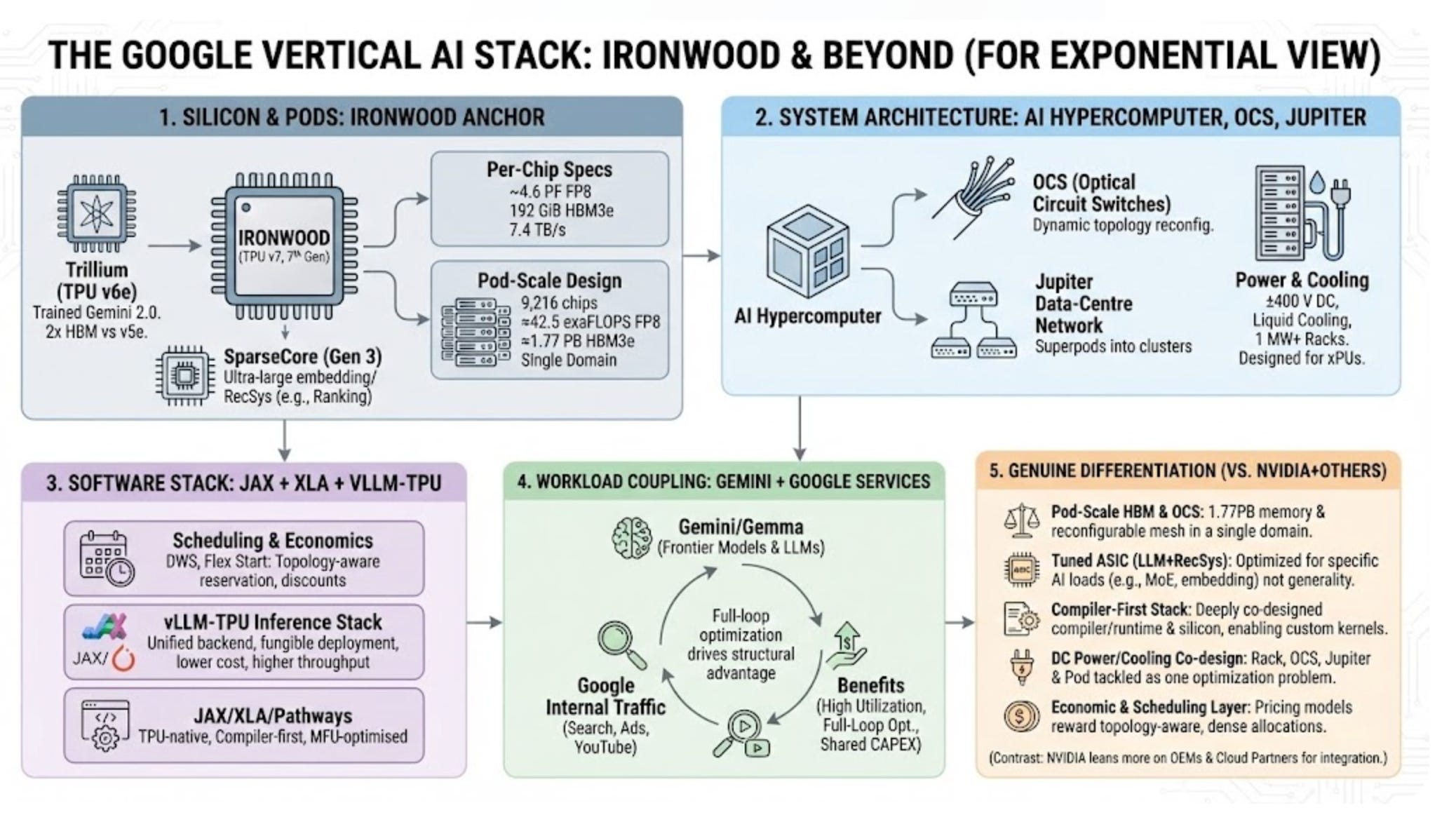
Gemini 3 is the dividend of that spending.
Crucially, the new model also addressed a criticism thrown at this sector. For the past few years, foundation model labs have bet on scaling laws, which state that spending more on data and compute reliably produces performance improvements. Many outside commentators claimed that scaling itself had failed. My view, last year, was that while other innovations would be welcome, scaling still had some years to go.
In the words of Google researcher, Oriol Vinyals, on the subject of pre-training scaling:
Contra the popular belief that scaling is over—the team delivered a drastic jump. The delta between [Gemini] 2.5 and 3.0 is as big as we’ve ever seen. No [scaling] walls in sight!
And as for post-training, the step where a trained model gets further refined, Vinyal’s is even more explicit:
Still a total greenfield. There’s lots of room for algorithmic progress and improvement, and 3.0 hasn’t been an exception.
What Google has shown is that scaling still works if you have the vertical stack to sustain the burn: infrastructure, data, researchers. To what extent can Anthropic or OpenAI follow that strategy?
The shape of intelligence
To understand whether Google’s gravity well is escapable, we need to look at what kind of mass creates AI gravity in the first place. Epoch AI has argued that intelligence isn’t monolithic; it’s a composite of general reasoning plus distinct, hard‑earned capabilities shaped by targeted data and training. In practice, that broad reasoning acts like Google’s diffuse gravitational mass, bending the competitive field1.
But there’s also a second category of contingent capabilities, spiky domain-specific skills like high-level coding, legal discovery, or proteomic analysis that don’t emerge by default. These require deliberate, expensive investment in specific data and training. Think of these as concentrated density in particular capability dimensions.

This changes everything about escape dynamics. In classical gravity, you can’t escape a larger mass, full stop. But in a composite system, you can achieve localized density that exceeds the dominant player’s density in specific dimensions, even while having far less total mass.
The customer choosing between them isn’t asking “who has more total mass?” They’re asking, “Who has the highest density in the dimension I care about?”
This is the key to the next five years. If capabilities are heterogeneous and orthogonal, you can’t build one “God Model” that maximizes every dimension simultaneously – even Google faces resource constraints.
Scale creates mass; specialization creates density. Pick one capability, invest hard, and win on price‑performance in that lane. That’s how you slip Google’s gravity – there will be no head‑to‑head fight.
Why Google owns “good enough”
Google commands three fronts simultaneously: (1) research labs rivalling OpenAI’s talent density, (2) infrastructure investment approaching $93 billion annually, and – most crucially – (3) distribution channels no startup can replicate.

The last of these, distribution, is becoming decisive. AI Overviews surface before two billion searchers each month, putting Gemini in front of more users in a day than most competitors reach in a year. Its assistant already claims 650 million monthly actives, second only to ChatGPT. Gemini doesn’t need to win every task; it just needs to meet the threshold of good enough inside products people already live in.