
🧠 AI’s $100bn question: The scaling ceiling
Scale is propelling the AI industry. But for how long?
By 2027, a single artificial intelligence model could cost $100 billion to train – a figure bigger than the GDP of two-thirds of the world’s countries. This staggering projection illustrates the breakneck speed at which AI development is scaling up, both in size and cost.
Scaling laws drive industry players; scaling works, as Anthropic’s Dario Amodei points out. But do these laws really hold? How long will they hold for? And what do they tell us about the next five years?
Azeem’s note: Some of this discussion is a little technical. I recommend reading the whole essay, or you can jump to the section called “You don’t have to be intelligent to be useful.”
Bigger is better
Modern AI is applied statistics, and statisticians now know that size matters. If you want to understand the average height of the men in the Netherlands, you’ll do a better job if you measure 100 people at random than if you measure one person at random. But at some point, what you gain from measuring every additional person yields very little useful insight into the average height. If I measure 2,000 people randomly, my estimate would have a margin of error of 0.31cm (or a bit more than a tenth of an inch). If I sampled a further 8,000 enticing subjects with tasty stroopwafels, my margin of error would only drop to 0.14cm. It’s hardly worth the effort, especially as I’ll have given all my stroopwafels away1.
However, machine learning, where systems learn from data, thrives on abundance. As this field, closely related to AI, co-developed alongside the increasing computation power of chips and the word-then-video vomit that is the Internet, researchers discovered that bigger was better and biggerer was betterer.
One milestone piece of work that changed how I understood this was Peter Norvig, Alon Halevy and Fernando Pereira’s classic paper, The Unreasonable Effectiveness of Data. This 2009 paper by Google’s Engineering Director and co-author of the canonical textbook on AI argued that simple models trained on vast amounts of data often outperform more complex models trained on less data. It emphasises the power of large datasets in improving model performance. Norvig’s insight pre-dated the deep learning revolution but foreshadowed the importance of big data in modern machine learning approaches.

A decade after Norvig’s insight, and several years into the deep learning wave, AI pioneer Rich Sutton chimed in with the “bitter lesson”, that general methods leveraging massive computation, particularly search and learning algorithms, consistently outperform approaches that try to build in human knowledge and intuition. At the time I wrote this
While it is tempting (and satisfying) for researchers to codify prior knowledge into their systems, eventually the exponential increases in computation favour approaches involving search and learning.
Both Norvig and Sutton identified that simple, general learning approaches across more and more data created more general models that could be more adaptable across various tasks. And boy, were they right. When Sutton wrote his paper in 2019, the average deep neural nets (as we called them then) had around 500m parameters2, about 100x smaller than today’s models.
You can distil scaling laws down to a simple principle: the bigger the model, the better its performance. We’ve seen this trend over time, with the amount of compute used by AI models increasing exponentially.
As we moved from traditional machine learning to deep learning through to large language models, the approach to scaling continued to hold. A key milestone was from OpenAI (and included one person who left to found Anthropic) with their study Scaling Laws for Neural Language Models. It’s a technical research paper, but there’s a killer line:
Performance depends strongly on scale, weakly on model shape. Model performance depends most strongly on scale, which consists of three factors: the number of model parameters N (excluding embeddings), the size of the dataset D, and the amount of compute C used for training.

Building on this concept, we highlighted research in EV#476 in June that made a striking observation: “An analysis of 300 machine learning systems shows that the amount of compute used in training is growing at four to five times per year – given the scaling laws, AI performance is likely to follow.” This exponential growth in computational resources devoted to AI training underscores the industry's commitment to pushing the boundaries of model performance.
Large language models specifically also show scaling laws, albeit logistically, which means that their performance improves following an S-shaped curve as we increase the size of language models and the amount of training data. Look at this evolution of OpenAI’s GPT model and how it has diminished marginal returns of compute to performance. Of course, this flattening is against a particular benchmark, MMLU, this may reflect the limitations of the benchmark. It might be that the models are improving in ways that are not captured by MMLU.
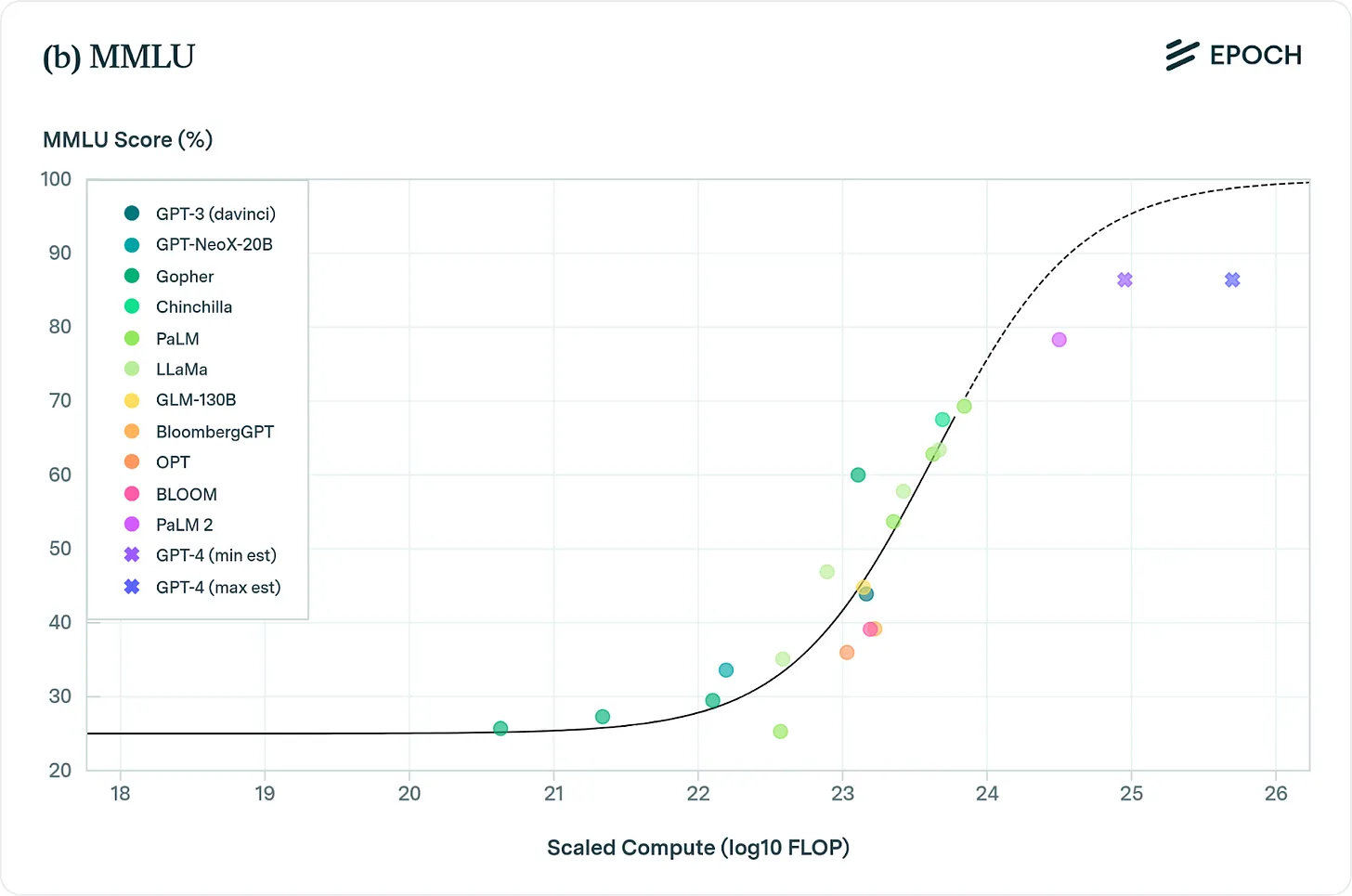
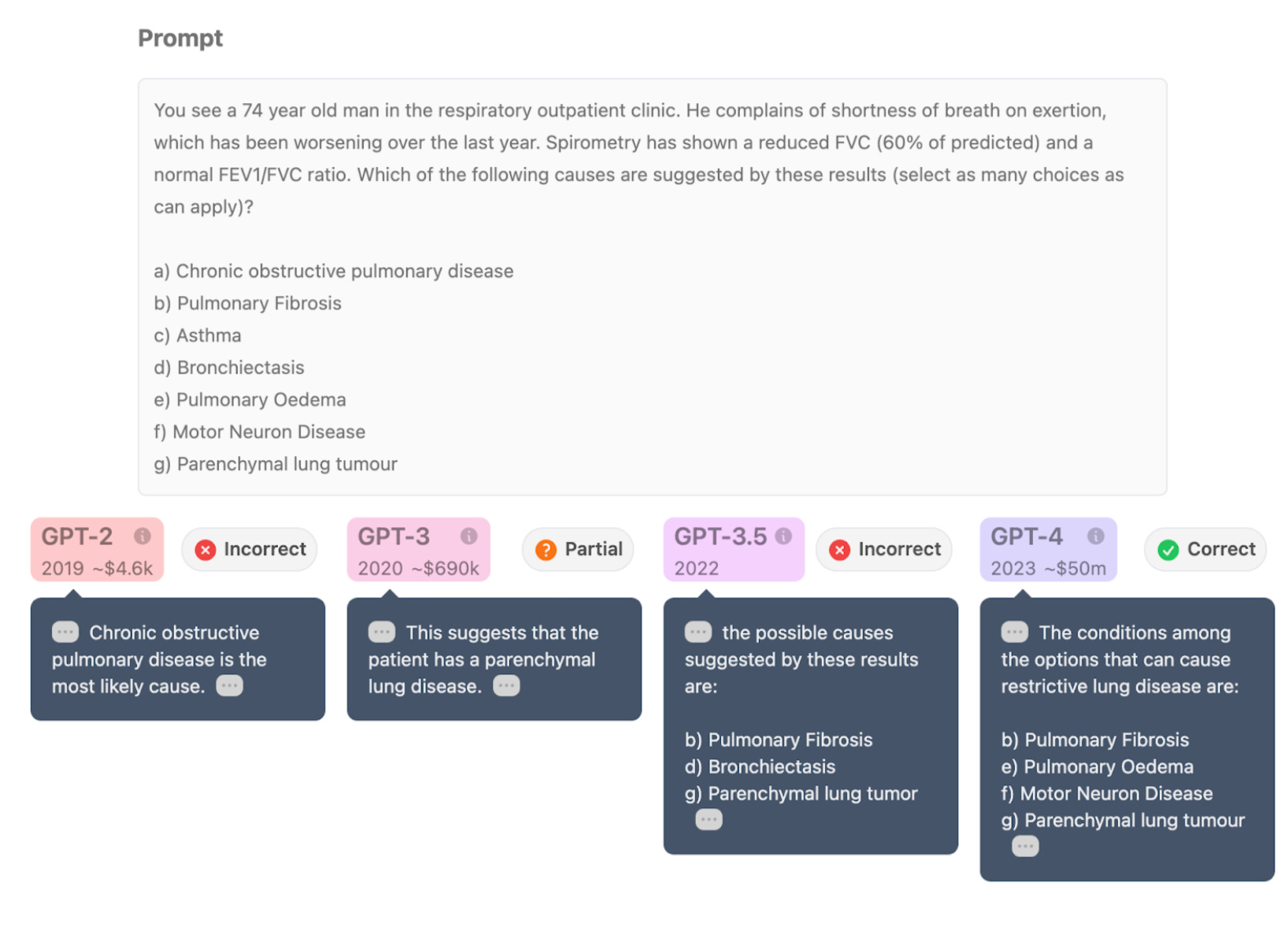
All of this sounds great. But what is scaling actually doing? Take a look at the example below. As AI models improved from GPT-2 to GPT-4, answers became increasingly sophisticated. They progressed from a single, incorrect guess to a more nuanced understanding of lung diseases. The latest model, GPT-4, provided the most accurate answer by correctly interpreting the patient’s symptoms and test results.
Seeing is believing — and in video generation models, scaling laws show their worth visually. While improvements in text models can be subtle, video models demonstrate the impact of scaling more dramatically. OpenAI’s Sora video model shows the importance of scale, here are some cute dogs to show you:
So scaling quite obviously is leading to improvement. But what is the actual quality of performance we see here? As Aravind Narayan in AI Snake Oil points out: “What exactly is a “better” model? Scaling laws only quantify the decrease in perplexity, that is, improvement in how well models can predict the next word in a sequence. Of course, perplexity is more or less irrelevant to end users — what matters is “emergent abilities”, that is, models’ tendency to acquire new capabilities as size increases.”
Simply put, scaling laws only predict how well the model predicts the next word in a sentence. No law describes capabilities will emerge. Despite this, one common view is that these larger models display emergent properties, that is, capabilities that are not designed for, that become available with increasing scale. They might have emerged, as seen with previous models, but not in a way anyone could predict3. An example, as proposed in this paper in Nature, is the emergence of analogical reasoning. These skills just popped up when the models got larger, surprising many.
The important point to take away is this: When AI companies talk about the importance of scale, they do so based on a longish research heritage that shows scale seems to work. This is not about bragging rights but about executing a design strategy that appears to work.
Scaling is holding… so far

Scaling laws don’t necessarily hold forever. Just look at Dennard Scaling. Also known as MOSFET scaling, it was a principle observed in the semiconductor industry from the 1960s to the mid-2000s, suggesting that transistors would keep their power density while getting smaller. The principle was key to maintaining Moore’s law for several decades. However, the principle began to break down in the mid-2000s as power leakage occurred once transistors got too small.
What might cause scaling to break?
Cost
We might not be able to afford it for one thing.
The trajectory of AI model costs is nothing short of staggering. Today, we're witnessing models with price tags approaching a billion dollars. But hold onto your hats - this is just the beginning.
Dario Amodei predicts next year’s models will hit the $10 billion mark. And after that? We’re looking at a whopping $100 billion. The question on everyone’s mind: Why this astronomical leap in costs?
At the heart of the cost explosion lies an insatiable appetite for computational power. Each new generation of AI models demands exponentially more compute, and compute doesn’t come cheap. Leopold Aschenbrenner’s analysis put these numbers into perspective: GPT-4 is estimated to have guzzled 2.1e+25 FLOPs of compute during training. How much do you need to spend to buy this amount of computing power? Around $40 million dollars. But it’s more complicated than that.
Firstly, you need to build a training cluster that can actually handle model training. For GPT-4, this cluster would require 10,000 H100-equivalent GPUs. These cost roughly $25,000 each. That’s $250 million in GPUs alone. But you still need to power the cluster, build an actual data centre, implement cooling and networking, etc. The total cost of the cluster is more like $500 million - already awfully close to Dario’s claim.
But here’s the kicker - the computer used by these LLMs is growing by 4-5x every single year. Historically, computer costs have declined by 35% per year. This means costs are roughly tripling each year. That means in 2025, we will have roughly a $10 billion dollar model, 2027, a $100 billion dollar model.
And as I said on daniel bashir’s podcast: “Global assets under management is only 100 trillion, so at 100 billion we’re only three more orders of magnitude away from all the assets that Humanity has to do your next training run.”
At some point, there will be an inevitable, hard economic limit. We haven’t reached that point yet. Microsoft reportedly invests $100 billion in their Stargate data centre, signalling confidence in future returns. But these returns haven’t shown yet - there is currently a $500 billion annual revenue gap between infrastructure investment and earnings, according to Sequoia Capital.
There has to be a significant upside to scaling to justify investment beyond Stargate. Remember, scaling laws show diminishing returns - for a given performance increase, we need to exponentially increase our investment. LLMs are industrial technologies; the investment needs to be recouped. I just ordered some hiking socks for my trip to Peru. I paid a couple of pounds extra for two-day delivery, but I was unwilling to pay £10 for next-day delivery as I didn’t need it. If the cost to build an LLM gets unaffordable (in the sense that we can’t get an economic return from the additional capability it offers), it probably won’t be built.
Data
Data is also an issue. Imagine the entire corpus of high-quality, human-generated public text on the Internet as a vast library. Epoch AI researchers estimate this library contains about 300 trillion tokens — that’s enough words to fill 600 million encyclopaedias.
They project that AI models will have read through this entire library sometime between 2026 and 2032. This estimate is more optimistic than their previous 2022 projection. It’s as if we discovered some hidden wings of the library and realised we could speed-read through some sections.

But even after our AI models have devoured every word in this vast library, we’ll face a new challenge. It’s like reaching the end of all known books — where do we go from there?
The challenge is compounded by a fundamental inefficiency in how current AI models learn. Research has revealed a log-linear relationship between concept frequency in training data and model performance. This means exponentially more data is required to achieve linear improvements in capability. Furthermore, the distribution of concepts in web-scale datasets follows an extremely long-tailed pattern, making it particularly difficult for models to perform well on rare concepts without access to massive amounts of data.
Some progress can continue through “undertraining” — increasing model parameters while keeping dataset size constant. However, this approach will eventually plateau. To maintain momentum beyond 2030, innovations will be crucial in areas such as synthetic data generation, learning from alternative data modalities, and dramatically improving data efficiency. Yet each of these potential solutions brings its own set of challenges. For instance, synthetic data generation raises questions about quality evaluation and preventing models from simply memorising synthetic examples rather than truly learning.
To add to the data challenge, a paper from Deepmind in 2022, known as the Chinchilla paper which emphasises not only the importance of more training data (arguing that many models trained to that data used too little data) but the importance of high quality data:
[O]ur analysis suggests an increased focus on dataset scaling is needed. Speculatively, we expect that scaling to larger and larger datasets is only beneficial when the data is high-quality. This calls for responsibly collecting larger datasets with a high focus on dataset quality.