
🔮 The jagged reality of AI – o3’s real world test
Eight messy tasks to test o3’s performance at work
o3 is somewhat of an enigma among the best AI models. When it launched last week, it caused a stir because using it not only delivered better output but it felt different. Economist Tyler Cowen called o3 “AGI.” Ethan Mollick wrote that the model resembles a “jagged AGI” – super‑human in some areas, surprisingly brittle in others. The pushback arrived just as fast: Bojan Tunguz’s satirical strawberry tweet and Colin Fraser’s algebra critique capture the gap between benchmarks and basic slips.

Benchmarks poured in. A VCT benchmark that measures the capability to troubleshoot complex virology laboratory protocols now has o3 in dominance with 43.8% accuracy vs. 22.1% that human PhD-level virologists scored. On ARC‑AGI v11, it solves more than half the secret set at a twentieth of the cost of the next best chain‑of‑thought model. Yet on the tougher ARC‑AGI v2 it barely clears 3%. The signal is getting harder to hear.

The more we measure AI, the less we seem to know. To cut through the noise, we stepped away from dashboards and put o3 – alongside Gemini 2.5 Pro, Claude 3.7 Sonnet and GPT-4o – through eight messy, real-world tests that reflect some of our day-to-day tasks:
Auditing codebases and building new features
Choosing the perfect laptop case
Crafting tricky international travel plans
Summarising dense essays
Reading scientific papers accurately
Executing research workflows
Translating chaotic brainstorming sessions into clear next steps
Ruthless fact-checking
Here’s what we learned from using the leading models in parallel.
Choosing the perfect laptop case
Nathan Warren began this test with a straightforward, consumer-facing prompt:
I need a laptop case for a MacBook Pro 17". Please find me the best product that fits my characteristics.
This vague prompt was his way of testing how well each model could scope a messy real-world query, ask the right clarifying questions and return a concise, high-confidence recommendation.
He scored each mode on three Cs: clarity, curation and confidence – awarding up to two points a piece. o3 began by firing five rapid‑fire questions about style, protection level, preferred materials, bonus features, budget and then delivered a shortlist of just two SKUs that met every constraint. The answer arrived in under three‑and‑a‑half minutes and included a neat comparison grid plus a one‑sentence “if/then” recommendation.
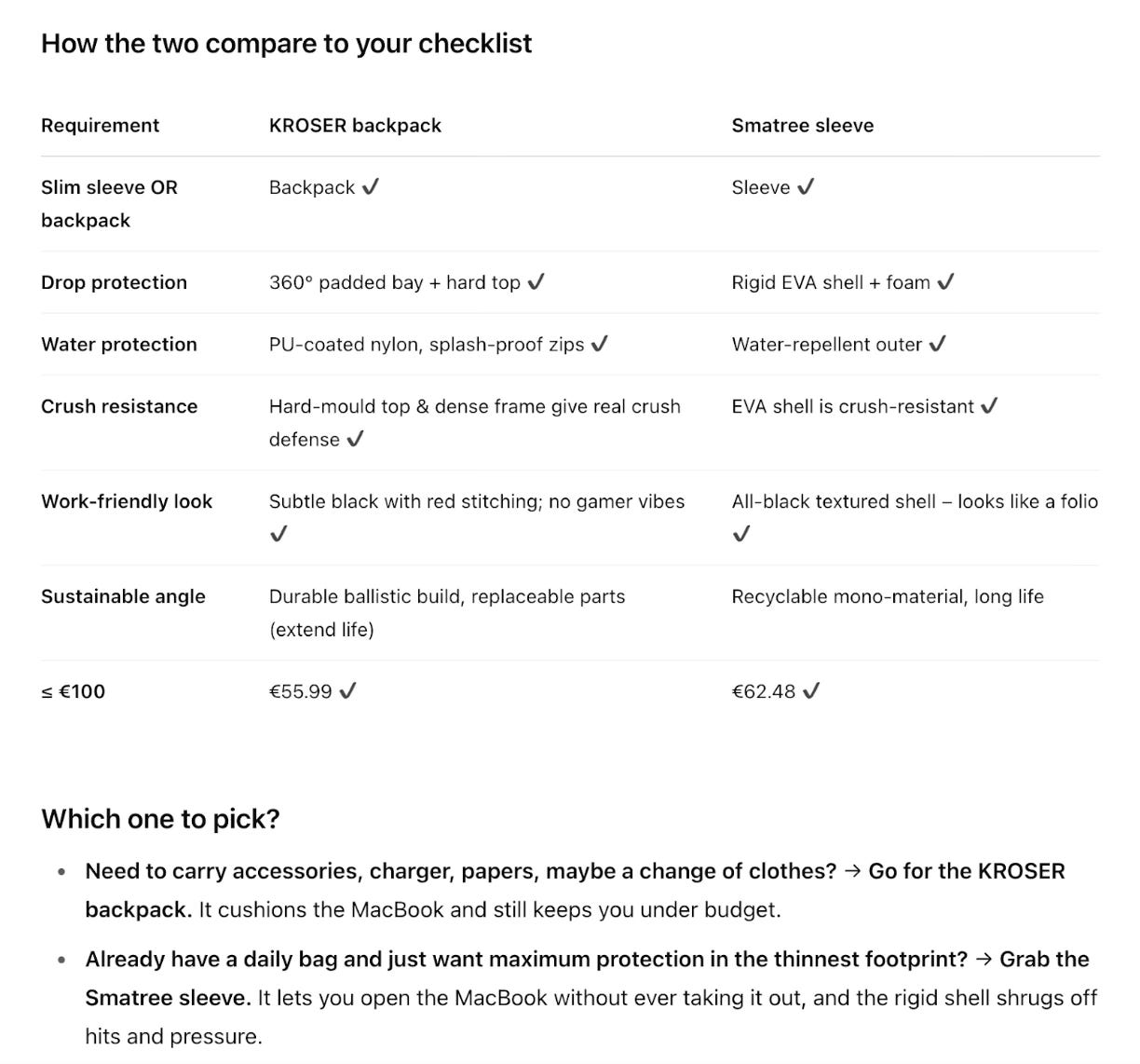
Gemini took the opposite approach. It was quicker, but asked no clarifiers, it just provided a selection of ten bags to choose from. Gemini felt like a search engine, o3 more of a personal concierge.

Auditing codebases and building new features
For the codebase audit test, Nathan chose to examine a large RAG-style project we use to create a searchable archive of our newsletter. The repository holds more than 2400 files and the only practical way to parse it is using OpenAI’s Codex or Anthropic’s Claude Code which lets the AI walk the file system, run shell commands, and read source in bulk. But because we don’t have API access to o3, we had to settle for o4-mini. Practically, this is what most people would use for coding anyway – it is much cheaper while being only slightly behind o3 on software engineering benchmarks.
Nathan graded performance on diagnosis accuracy, implementation advice, and whether the proposed patch ran on the first try – two points each, for a maximum of six. o4-mini received maximum marks. It loaded the full directory tree, crawled 2 400 files easily and behaved like a seasoned mechanic. It listed modules, in‑lined code and flagged exact inconsistencies. On the other hand, Claude Sonnet 3.7 offered a fine but higher‑level review, more driving‑impressions than under‑the‑hood specifics. Nathan gave it a 4/6.

The second part of Nathan’s coding test was to get the models to build a new feature. He handed both contenders the same brief: “After retrieval, run an LLM ‘aggregate & summarise’ step so you return a concise answer rather than raw chunks.” Claude 3.7 Sonnet treated it like a pull‑request ticket. In a single burst it created a tiny helper that grabs the top search chunks, feeds them to an OpenAI call and prints the resulting blurb. The patch slotted in cleanly: no hard‑coding of keys, clear logging and a new --raw flag for anyone who still wants the old behaviour. Nathan hit enter, the code compiled and the CLI spat out a neat three‑sentence answer – job done in under four minutes, API cost ¢68.
o4‑mini followed the same brief but took a slightly bumpier road. It altered fewer lines, ran faster and even wrote an “agent‑readable” guide inside the comments, yet it called an outdated OpenAI function. Fixing that import took thirty seconds, after which the feature worked exactly as advertised. Total bill: $1.
Both models could wire up a real feature in a single conversation, but Claude was slightly more robust. o4‑mini remains the fastest diagnostic mechanic, while Claude is still the safer pair of hands when the code needs to ship today.
Plan tricky international travel
The British Airways website is one of my most frequently visited sites. My trips often involve tight turnarounds and a dash to another commitment. So far, the large language models have been utterly useless. They haven’t browsed the web; they can’t plan through the combinatorial complexity of trip routings and they lack the nuance and understanding I expect.

One example, I generally prefer the earlier flight to the later flight, except when coming back from San Francisco as the early BA flight is a janky A380 but the later one gets a more comfortable 777.
My current travel test to the LLMs is to respond accurately to this made-up challenge:
I am in Tianjin on 26 June finishing a meeting by 11.45am. I must be in Watford, UK for 11am on Friday 27 June. What travel options do I have? Business class preferred.
This isn’t straightforward. It is a multimodal query, involving combinations of trains, taxis, planes and stop-overs in potentially many countries. It’s reasonably easy for me to solve: leave Beijing on a flight that gets into London by 9pm UK time; or take an overnight routing via one of the likely candidate cities (Helsinki, Istanbul, Dubai, Doha, Abu Dhabi, Paris or Frankfurt) and make sure you can get a flight first thing in the morning to London.
Most AI systems fail even if they try hard. Gemini 2.5 with Deep Research was like a breathless intern. It went off and boiled the ocean, eagerly offering me a 5500-word report which was completely wrong. So, I wanted to know, how does o3 compare?
It was remarkable, as you’ll see further below.
o3 understood the possibilities and responded in a structured format: to arrive in London in the evening of the 26th and stay overnight. Or take an overnight flight (via Hong Kong or Istanbul) to arrive in London in the morning, with time to travel to Watford, a town outside London. It even considered flying private.