
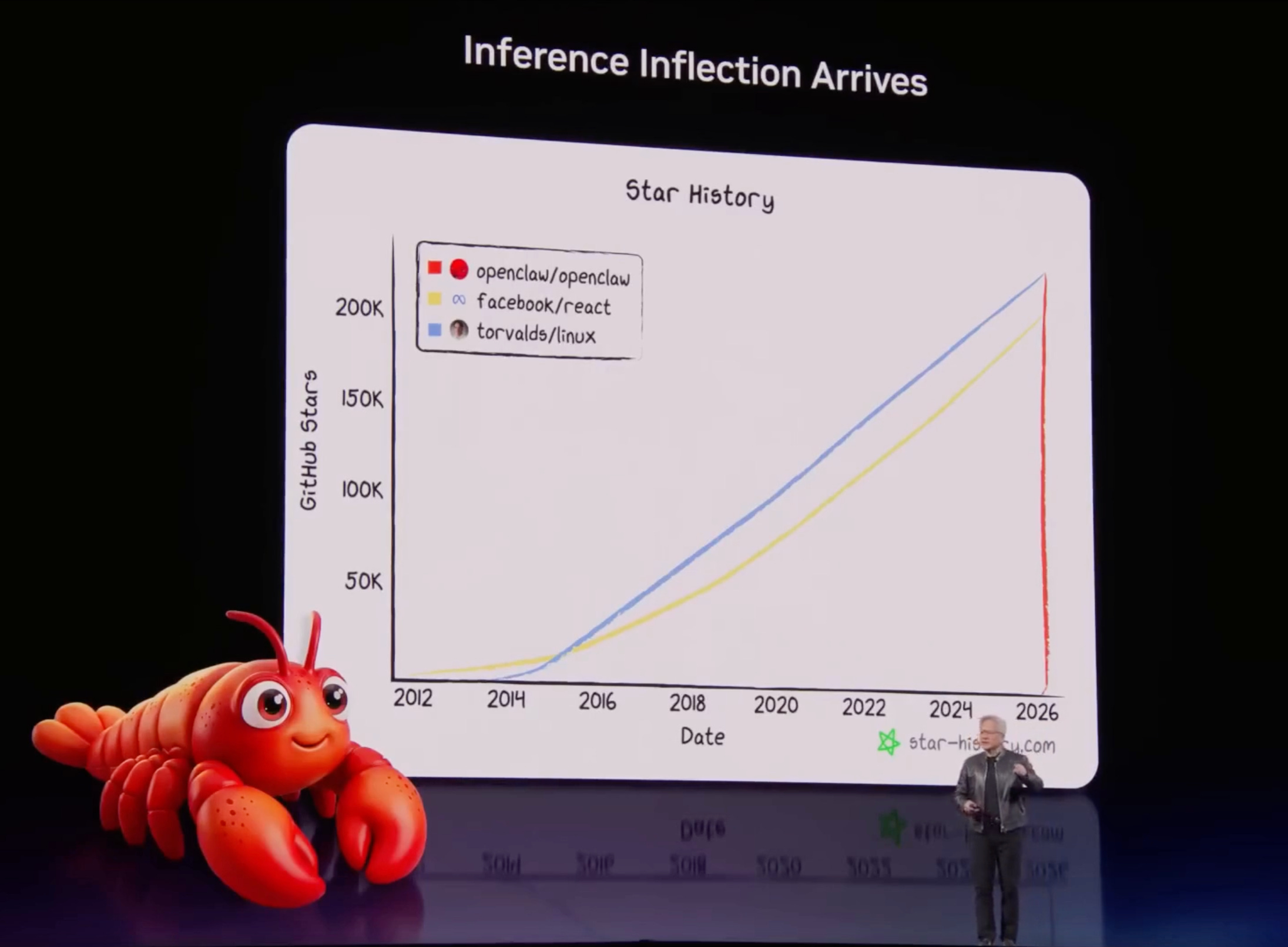
🔮 Jensen’s OpenClaw thesis
The inference transition changes everything
Jensen Huang delivered a stunning performance at this year’s GTC. I want to reflect on one thing Jensen said that tells us a lot about the near future of AI:
Every company needs an OpenClaw strategy.
OpenClaw is the most exciting piece of technology I have seen since the web browser in 1992. Jensen reached the same conclusion independently, from the other end of a trillion-dollar supply chain. Today, I want to explain what the shift Jensen described means for the AI economy, for your organization and for the window that is already closing.
The end of the training era
When ChatGPT arrived in late 2022, the underlying economics of AI were dominated by training. Building a large language model required astronomical compute – 10²³, 10²⁴ floating point operations or more. GPT-4 reportedly cost over $100 million to train. Meta’s Llama series consumed thousands of NVIDIA chips running for months. Data centers were configured for maximum parallelism, maximum throughput, everything optimized for the one-time act of building a model.
But training is, by definition, a one-time event. A model is trained once and then run — inferred against, in the technical vocabulary — millions or billions of times by actual users. And inference has completely different economics from training.
This is what makes Groq worth $20 billion for NVIDIA. When you send a prompt to a language model, two things happen. First, the pre-fill phase when the model reads and processes your input tokens simultaneously, in parallel. This is enormously compute-intensive and it’s where GPUs shine – they were built for graphics. But then comes the decode phase, the generation of the response, word after word, like a slow teletype. The model produces tokens one at a time, each depending on the previous one. This cannot be parallelized. It is structurally sequential. The bottleneck here is memory bandwidth. How fast can you stream the model’s weights from memory for each individual token step? Thousands of GPU cores sit largely idle, waiting on memory reads, just to produce one token at a time.
GPUs were not built for this. As the AI economy shifts from building models to running them constantly at scale – for billions of users and, crucially, for millions or billions of agents – GPU inefficiency in the decode phase becomes a serious structural problem. Groq’s chips are designed specifically for inference throughput. The combined Vera Rubin and Groq architecture, due later this year, will deliver a 35-fold improvement in throughput per megawatt versus NVIDIA’s current Blackwell chips. That’s a signal about what NVIDIA believes the inference market is about to become.
How large is large? As users shifted from simple chatbot interactions to reasoning models and now to agentic systems that run complex, multi-step workflows, compute applied per user interaction increased by a factor of 10,000. At the same time, the number of users deploying AI systems at scale increased by a factor of 100. The outcome is a million-fold expansion in inference demand over roughly two years.
A million times. In two years.
In summer 2024, I was applying perhaps 100,000 to 150,000 tokens per day – heavy usage by the standards of the time. Two weeks ago, my AI chief-of-staff R. Mini Arnold had reached 100 million tokens per day on average. That’s three orders of magnitude in less than two years.
On Monday, working with R. Mini Arnold and its four sub-agents – R. Veblen for book research, R. Simmons for portfolio management, R. Bradlee for editorial analysis, R. Gulbenkian for AI economy frameworks – I applied 870 million tokens in a single day. Close enough to a billion. My average for the past week has been well above 200 million per day, seven days a week. And this is what work looks like when you have the right harness, OpenClaw.
The harness is the revolution
The standard debate about the AI investment and AI in general has mostly been about the wrong thing. The boosters and the sober-minded researchers at frontier labs argue that capability improvements are not near a wall. On the other end are the skeptics, who point to diminishing returns on training compute and say the AI wave is speculative. Both camps are measuring the performance curve and missing the diffusion curve. And the diffusion curve is the one that determines whether the trillion-dollar infrastructure bet is justified.
Consider the internal combustion engine. A mechanical engineer with access to a bare engine can do something useful – connect it to a generator, build a hedge trimmer, strap it to a bicycle. Impressive. But what makes the internal combustion engine transform an economy is the harness: the automobile. The car is not a clever engine. It’s a chassis, seats, a windscreen, a steering system, and yes, a terrible hi-fi. But that harness is what makes people use the engine constantly, for decades, at scale.
Would you rather have a race-tuned Ferrari engine sitting on your lawn, or a ten-year-old petrol engine actually in a car you can drive somewhere useful? The harness wins every time.

For AI, the harness moment happened at the tail end of 2025. Claude Code began to work reliably enough that you could leave it running overnight and trust what it had done in the morning. Not perfectly, but reliably enough. And that threshold, that “I can leave it to its own devices” threshold, changed everything. It changed what users asked AI to do. It changed how long tasks ran. It changed the token usage profile of every organization that crossed it.
Now, OpenClaw is the harness for the next layer.
What the inference economy demands of organizations
The practical question is what all this means for a firm trying to make sensible decisions in 2026. And here I think the consensus response – more pilots, careful evaluation, measured rollout – is dangerously behind the curve.
Tokens are not an IT line item. They are a productive input, as fundamental to knowledge work as electricity or office space. The organizational error most large companies are making right now is treating token budgets as an IT function – a cost center to be rationalized and kept away from the business units. This is wrong. It is the equivalent of requiring engineers to book time on the engine through the facilities department.