
🔮 AI in 2030: Part II
The next leap is scheduled
In 2020, the most powerful publicly-known AI model needed a small data center to train. By 2029, the same job will fit on a laptop because of an interlocking layer of exponential trends, gifting us more processing power and more efficient software.
When we put numbers to that stack of exponentials, the future stops being speculative; it becomes, to some extent, scheduled.
Azeem described what that might feel like in his essay over the weekend. Your phone running GPT-5-class models, accessible whether you are online or not. Agents will handle tasks that would take you weeks of deep work for less than a dollar.
But what gives us the confidence to say any of that? Words are easy to put on the page. To build greater certainty, we looked at the drivers of the underlying capabilities of AI systems: the availability of compute and the improvement in models and how they might match up.
How likely is it that the specific trends we’ve experienced in these different domains continue? And what happens if they do?
Here’s a detailed breakdown to help you understand the path from here to there.
The compute explosion
Capital is racing ahead of Moore’s Law. AI infrastructure, particularly data center packed with accelerator silicon, now represents the single largest slice of the capital expenditure budgets across hyperscalers. Microsoft currently leads the pack, having amassed 485,000 of Nvidia’s $25,000 Hopper chips. They are closely trailed by Meta’s ~350,000 H100s, scaling towards an installed base equivalent to nearly 600,000 H100s.
This build-up precedes even more substantial expansions like the Stargate project, a $500 billion AI infrastructure investment targeting more than one million GPUs by 2029, drawing 5 GW of power, about the same as Los Angeles at peak times. It isn’t just the US – Saudi Arabia announced Humain, an AI company, with an investment of $15 billion from AWS and AMD. This complements a deployment of 18,000 of Nvidia’s state-of-the-art GB300s. The UAE has signalled its own ambitions.
This accelerated growth of compute used specifically for training frontier AI models surpasses the trajectory historically observed under Moore’s Law. For context, Grok-3 alone was estimated to be trained with roughly 4-5 × 10²⁶ FLOPS – approximately 1,300-1,600 times the compute used by GPT-3. The pace and scale of recent advancements is extraordinary.

Epoch AI, a research group, found that compute training was doubling every 5.4 months, substantially outpacing the traditional Moore’s Law doubling interval of 18 months. This comes before considering the additional compute required for post-training of these models to fine-tune their abilities and “personality”.
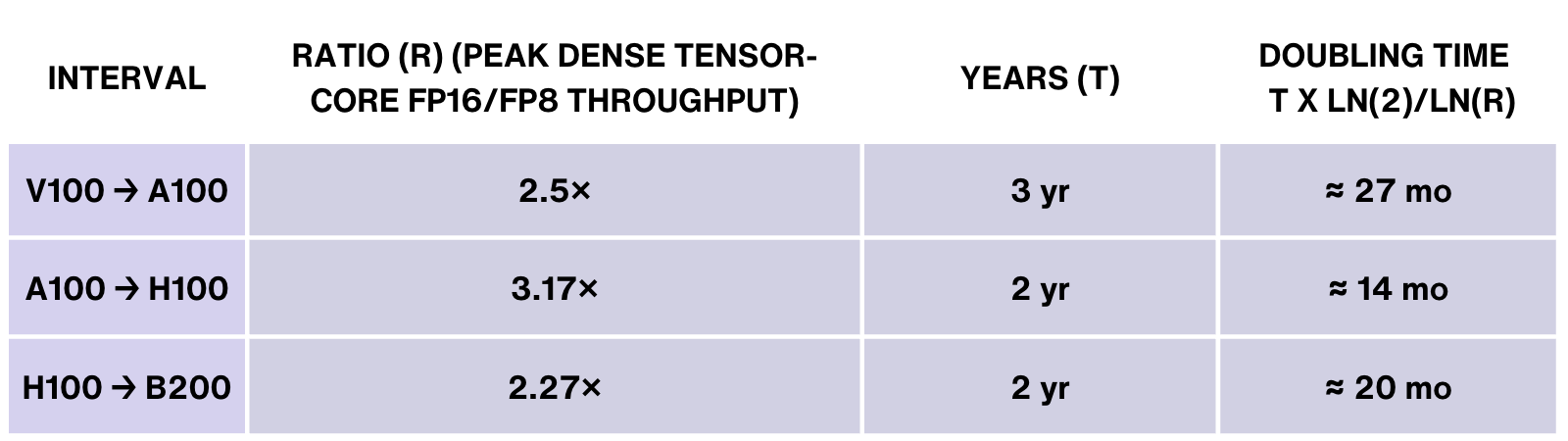
Silicon economics also remains exponential. Each GPU generation nearly doubles performance every 18 months. Nvidia’s latest Blackwell B200 chips provide up to 2.5x the throughput of previous-generation Hopper H100s.
Thanks to ongoing improvements in computing hardware and efficiency, AI systems will become much more energy-efficient. By the end of the 2020s, the number of floating-point operations per watt (FLOP/Watt) - a measure of how efficiently a system performs computations – could improve by a factor of 35 compared to 2020 levels. This projection compares the efficiency of Nvidia’s A100 chip (a 2020 benchmark) with expected advances by 2030, considering historical trends and potential unlocks with reversible computing architectures in the late 2020s.

We can trace this trajectory through key inflection points, such as the launch of Nvidia’s H100 in 2024 and the upcoming Vera Rubin and Feynman architectures. These successive GPU generations are expected to cumulatively drive a 2,000-fold increase in compute availability by 2030.
This rapid progress isn’t limited to data centers. On-device computing power in laptops and smartphones is also accelerating, roughly doubling every two years.

If current trends hold, by 2027 the computational power packed into a consumer laptop could rival the inference performance of a 2020-era A100 GPU and bring once-elite AI capabilities into everyday personal devices.
Algorithmic efficiency revolution
Alongside hardware gains, AI models themselves are becoming more efficient. Between 2012 and 2023, research showed that the compute required to reach a fixed performance level halved roughly every eight months.

More recent estimates from Epoch AI suggest this trend is continuing, with efficiency now improving by a factor of three each year.