
🔮 Kimi K2 is the model that should worry Silicon Valley
What Moonshot’s new model tells us about China’s AI game
In October 1957, Sputnik 1 proved that the USSR could breach Earth’s gravity well and shattered Western assumptions of technological primacy. Four years later, Vostok 1 carried Yuri Gagarin on a single loop around the Earth, confirming that Sputnik was no fluke and that Moscow’s program was accelerating.
In today’s AI, DeepSeek plays the Sputnik role – as we called it in December 2024 – as an unexpectedly capable Chinese open‑source model that demonstrated a serious technical breakthrough.
Now AI has its Vostok 1 moment. Chinese startup Moonshot’s Kimi K2 model is cheap, high-performing and open-source. For American AI companies, the frontier is no longer theirs alone.

In today’s analysis, we’ll get you up to speed on Kimi K2, including:
What Kimi K2 is and how it works – its architecture, optimizer and training process, and how it was developed inexpensively and reliably on export-controlled chips.
Why Kimi K2 matters strategically – how it shifts the centre of AI gravity, particularly on efficiency, and why it’s a wake-up call for US incumbents.
What comes next – the implications for open-source versus closed-source, AGI strategy, and China’s growing AI advantage.
What’s so special about Kimi K2?
First off, it’s not a Kardashian 😆. But it is engineered for mass attention. Only here, the mechanism is literal. Like DeepSeek, Kimi K2 uses a mixture-of-experts (MoE) architecture, a technique that lets it be both powerful and efficient. Instead of processing every input with the entire model (which is slow and costly), MoE allows the model to route each task to a small group of specialized “experts.” Think of it like calling in just the right specialists for a job, rather than using a full team every time.
K2 packs one trillion parameters, the largest for an open-source model to date. It routes most of that capacity through 384 experts, of which eight – roughly 32 billion parameters – activate for each query. Each expert hones a niche. This setup speeds the initial pass over text while regaining depth through selective expert activation to deliver top‑tier performance at a fraction of the compute cost.
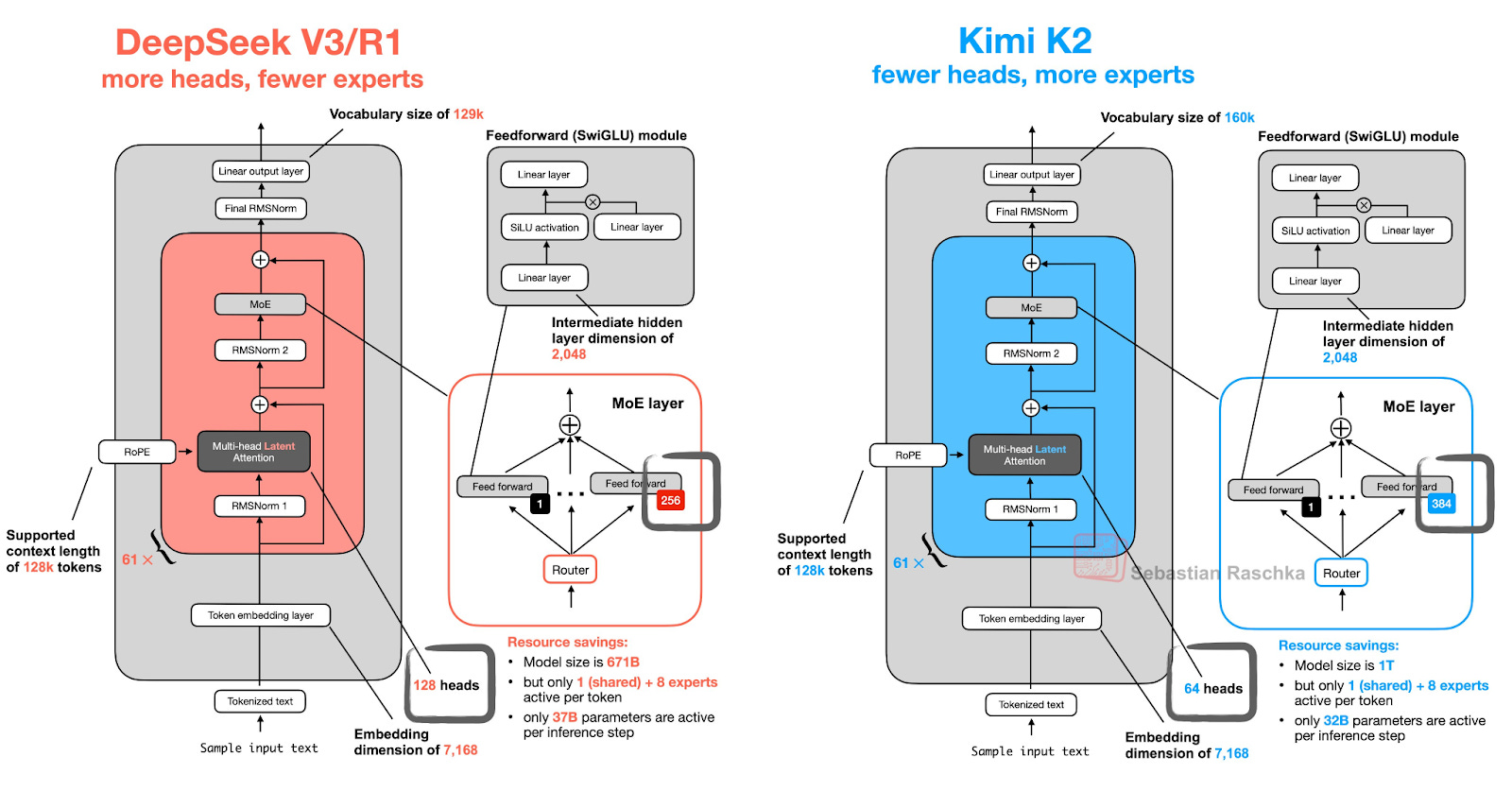
But Kimi K2 didn’t start from scratch. It built directly on DeepSeek’s open architecture.
One of the most beautiful curves in ML history
It’s a textbook case of the open innovation feedback loop, where each release seeds the next and shared designs accelerate the whole field. That loop let Kimi K2 focus on the next innovation: its approach to training.
Training a large language model is like adjusting millions of tiny knobs – each one a parameter that nudges the model toward fewer mistakes. The optimizer decides how large each adjustment should be. The industry standard, AdamW, updates each parameter based on recent trends and gently nudges it back toward zero. But at massive scale, this can go haywire. Loss spikes – sudden jumps in error – can derail training and force costly restarts.
Moonshot’s MuonClip model introduces two innovations to improve the training and stability of AI systems.
First, it adds “second-order” insight, meaning it doesn’t just look at how the model is learning (via gradients), but also how those gradients themselves are changing. This helps the model make sharper, more stable updates during training to improve both speed and reliability.
Second, it adds a safety mechanism called QK-clipping to the attention mechanism. Normally, when the model calculates how words relate to each other (by multiplying ‘query’ and ‘key’ weights), those values can sometimes become too large and destabilize the system. QK-clipping caps those scores before they spiral out of control, acting like a circuit-breaker to keep the model focused and stable.
The result is “[o]ne of the most beautiful loss curves in ML history,” as AI researcher Cedric Chee put it. Training runs longer, it is more reliable and at an unprecedented scale for open-source.

This would have unlocked massive compute savings. Research from earlier this year estimates that Muon optimizers are roughly twice as computationally efficient as AdamW. This would have been a major help with export controls. Moonshot likely had to train K2 on compliant A800 and H800 hardware instead of the flagship H100s. The training ran on more than 15.5 trillion tokens, roughly 50x GPT‑3’s intake, without a single loss spike, catastrophic crash or reset. Given this, training was likely relatively inexpensive. It probably cost in the low tens of millions of dollars.
Beyond its architecture and optimizer, Kimi K2 was trained with agentic capabilities in mind. Moonshot built simulated domains filled with real and imaginary tools, then let competing agents solve tasks within them. An LLM judge scored the outcomes, retaining only the most effective examples. This taught K2 when to act, pause, or delegate. Even without a chain-of-thought layer, where the model generates intermediate reasoning steps before answering, the public Kimi‑K2‑Instruct checkpoint performs impressively on tool use, agentic, and STEM-focused benchmarks, matching or exceeding GPT-4.1 and Claude 4 Sonnet. Quite differently, It also ranks as the best short‑story writer.

Artificial Analysis notes that Kimi K2 is noticeably more verbose than other non-reasoning models like GPT‑4o and GPT‑4.1. In their classification it sits between reasoning and non‑reasoning models. Its token usage is up to 30 % lower than Claude 4 Sonnet and Opus in maximum‑budget extended‑thinking modes but nearly triple that of both models when reasoning is disabled.
Still, it currently doesn’t leverage chain-of-thought reasoning. Moonshot will likely release a model which adds this in the future. If it mirrors DeepSeek’s leap from V3 to R1, it could close the gap with closed-source giants on multi-step reasoning and potentially become the best overall model. But that’s not guaranteed.
Even with its verbosity, pricing remains one of Kimi K2’s key strengths. Moonshot has taken DeepSeek’s foundation and improved it across the board, pushing out the price‑performance frontier. The public API lists rates at $0.15 per million input tokens and $2.50 per million output tokens. This makes it 30% cheaper than Gemini 2.5 Flash on outputs, and more than an order of magnitude cheaper than Claude 4 Opus ($15 in / $75 out), GPT‑4o ($2.5 in / $10 out), or GPT‑4.1 ($2 in / $8 out).
However, in practice, K2’s higher token output makes it more expensive to run than other open-weight models like DeepSeek V3 and Qwen3, even though it significantly outperforms them.

Still, it sits right on the edge of the cost-performance frontier, as it delivers near-frontier capability on agentic and coding tasks at unit economics that make sense for everyday product workloads. And those economics improve further if you run it on your own hardware.
As I said in my introduction, Kimi K2 is China’s Vostok 1 moment: it is proof that China can not only match but push forward the state of the art under real-world constraints. And like Vostok, what matters most isn’t just the launch – but the chain reaction it sets off.
Why Kimi K2 matters
Within weeks of Gagarin’s Vostok flight, the US scrambled to close the gap. Alan Shepard’s 15‑minute Freedom 7 hop on 5 May 1961 put the first American in space. Just twenty ddays later, President John F. Kennedy asked Congress to commit the nation to landing a man on the Moon before 1970.
K2 has now confirmed that China leads in AI‑efficiency innovations. DeepSeek R1 proved that you could graft full chain‑of‑thought reasoning onto a sparse mixture‑of‑experts model simply by inventing a new reinforcement objective – Group‑Relative PPO – and reducing the reliance on expensive human‑written dialogues.
Last week, Kimi K2 repeated the trick on the training side: the MuonClip optimizer keeps the gradient so well behaved that a trillion‑parameter MoE can process 15.5 trillion tokens without a single loss spike while using about half the FLOPs of AdamW. Two genuine algorithmic advances, six months apart, both published under permissive licenses, have shifted the centre of gravity for efficiency innovation to Beijing rather than Palo Alto.
The next question is whether that shift actually matters.
