
🔮 You’ve been prompting wrong this whole time
The leaked rulebook that shows how AI labs really prompt
Many of us feel fluent in prompting AI by now, but still feel frustrated when the results fall short. The issue usually isn’t the model. It’s how we talk to it.
Too often, we fall into what developer Mitchell Hashimoto calls “blind prompting”, treating the AI like a helpful colleague instead of instructing it with purpose and structure. In one 2023 study, participants who got a decent result early on assumed their prompt was “done,” and never refined it further.
If you hired a new team member and gave them only vague tasks with no feedback, you wouldn’t be surprised if they struggled. The same goes for AI. Models need context. They need iteration. And they benefit from review, correction and calibration, just like people do. And as AI becomes one of the most important inputs in modern work, it’s time to start managing it as such.
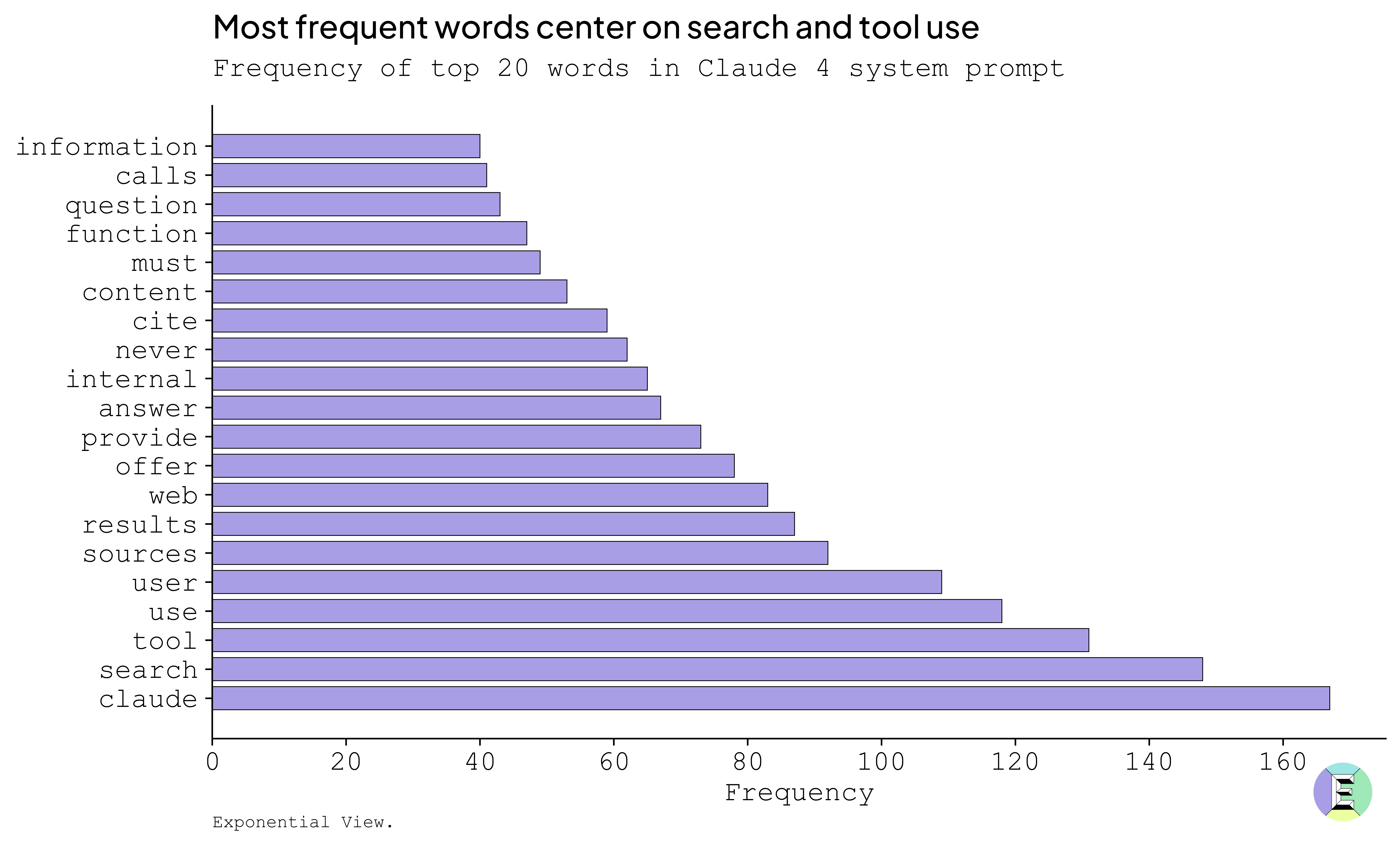
There are now dozens of system prompts from labs and startups floating around online. AI labs have invested millions of dollars in developing them. They’re all expertly crafted and sophisticated, but Claude 4 is one of the most extensive to date. Claude’s system prompt is at 24,000 tokens, or ~9,700 words, 453 sentences in length. For comparison, the Gemini-2.5-Pro and o3_o4-mini leaks stand at 1,636 words and 2,238 words, respectively.
For all of you who want to improve your skills, studying these leaks might be one of the best routes available. Our team has studied Anthropic’s internal guide to Claude 4 to identify seven key rules, along with examples (included in the leak and our own in italics), that will enhance your prompting game, guaranteed.

Rule 1: You are an instructor, act like it
You might not realize it, but being specific, with clear, formatted instructions, can dramatically improve your AI results. Even subtle tweaks in wording can improve the accuracy by as much as 76%. The Claude system prompt clearly defines that the standard responses should be in paragraph format, unless the user specifies otherwise:
Claude responds in sentences or paragraphs and should not use lists in chit chat, in casual conversations, or in empathetic or advice-driven conversations. In casual conversation, it's fine for Claude's responses to be short, e.g. just a few sentences long.
...
If Claude provides bullet points in its response, it should use markdown, and each bullet point should be at least 1-2 sentences long unless the human requests otherwise. Claude should not use bullet points or numbered lists for reports, documents, explanations, or unless the user explicitly asks for a list or ranking. There are also numerous stylistic notes instructing Claude precisely how to craft its responses in different contexts, such as:
Claude is able to maintain a conversational tone even in cases where it is unable or unwilling to help the person with all or part of their task.Conversely, Claude remains thorough with more complex and open-ended questions. And for those seeking more affective conversations, the system prompt writes:
For more casual, emotional, empathetic, or advice-driven conversations, Claude keeps its tone natural, warm, and empathetic.How can we make use of this? When prompting your large language model (LLM), clearly define the AI’s role, your exact task and the desired output. This can include the format of the output in terms of the style, length, and formatting, to more precisely get your desired result.
You are a senior copy editor. Task: rewrite the following 200-word blog intro so it’s clear, concise, and in plain English. Output: one paragraph, no bullet points, max 120 words.Rule 2: DON’T do that; do use negative examples.
It is becoming more well-known that providing clear examples of what you want can result in more aligned outcomes with your goal. However, we also see that describing what not to do can be of benefit, too. These crop up multiple times in the Claude system prompt, such as in the following example:
Any calculations involving numbers with up to 5 digits are within your capabilities and do NOT require the analysis tool.Alongside this are some examples to guide Claude on where not to use the analysis tool:
Do NOT use analysis for problems like "4,847 times 3,291?", "what's 15% of 847,293?", "calculate the area of a circle with radius 23.7m" In fact, the system prompt contains a larger frequency of the word “never” compared to “always”, with 39 instances of the former versus 31 for the latter. The word “always” doesn’t even make it into the top 20 words in the prompt, while “never” has the 13th highest frequency.
Although these arbitrary examples of what not to do may seem random, they help to guide the tool behaviour of the LLM, leading to faster outputs and fewer tokens needed to process the task.
How can we make use of this? The context windows (available window of attention for an LLM) are growing bigger and bigger. For complex problems, provide the LLM with examples of what you do and do not want, to clarify the expectations and improve accuracy.
Edit this paragraph for a general audience. DON’T use jargon like ‘transformer’, ‘parameter’, or ‘hallucination’. If any slip through, revise the sentence immediately.Rule 3: Provide an escape hatch
By now, we all know that LLMs tend to hallucinate if they don’t know the right answer. Aware of this, Anthropic has opted to include a line to ensure that Claude can send the user to the best place for the latest information.
If the person asks Claude about how many messages they can send, ... , or other product questions related to Claude or Anthropic, Claude should tell them it doesn't know, and point them to 'https://support.anthropic.com'.Providing an “escape hatch” can help reduce hallucinations, allowing the LLM to admit where it is lacking in knowledge instead of attempting to answer (and often being very convincing even if the result is completely incorrect).
How can we make use of this? Explicitly ask the LLM to mention “I don’t know” if it does not have the knowledge to comment. Additionally, you can provide another “hatch” by adding that it can and should ask for clarifying information if needed to provide a more accurate answer.
If you’re < 70 % confident about a style rule, respond: ‘I’m not certain—please verify in theAP Stylebook or Chicago Manual of Style before editing. Otherwise, edit normally.Rule 4: Search strategically
Claude spends 6,471 tokens, nearly a third of its system prompt, just instructing itself how to search.