
💡 The $100 trillion productivity puzzle
AI capabilities surge while businesses crawl—why the gap exists & how to close it
We are only six months into the year, yet AI has already outpaced two decades of ordinary tech cycles. In January, DeepSeek shook the world. Google, OpenAI and Anthropic quickly followed with next-generation models, ones which could command software tools on the internet.
The first wave of agents then appeared: ManusAI—until recently an unknown start-up—unveiled an agent that can autonomously tackle complex tasks, while Anthropic launched Claude Code, a multi-agent system many developers call a dream. The lab race is heating up, but two years after ChatGPT’s debut, the macro-productivity numbers remain stubbornly flat.
This is the capability-absorption gap: frontier labs are racing ahead faster than the traditional economy can keep pace. The current generation of AI is already powerful enough to remake how we work, yet firms are absorbing these capabilities far more slowly than labs are enhancing them. I don’t blame them. Prices halve every six months; models remain stochastic, which complicates reliability; and managerial know-how is scarce.
In today’s post, we will explore this gap and what businesses can do about it.
How far capabilities have already outpaced us
The scoreboard is unambiguous: nearly every public benchmark has moved upward since last year, making previous standards of excellence look decidedly ordinary.
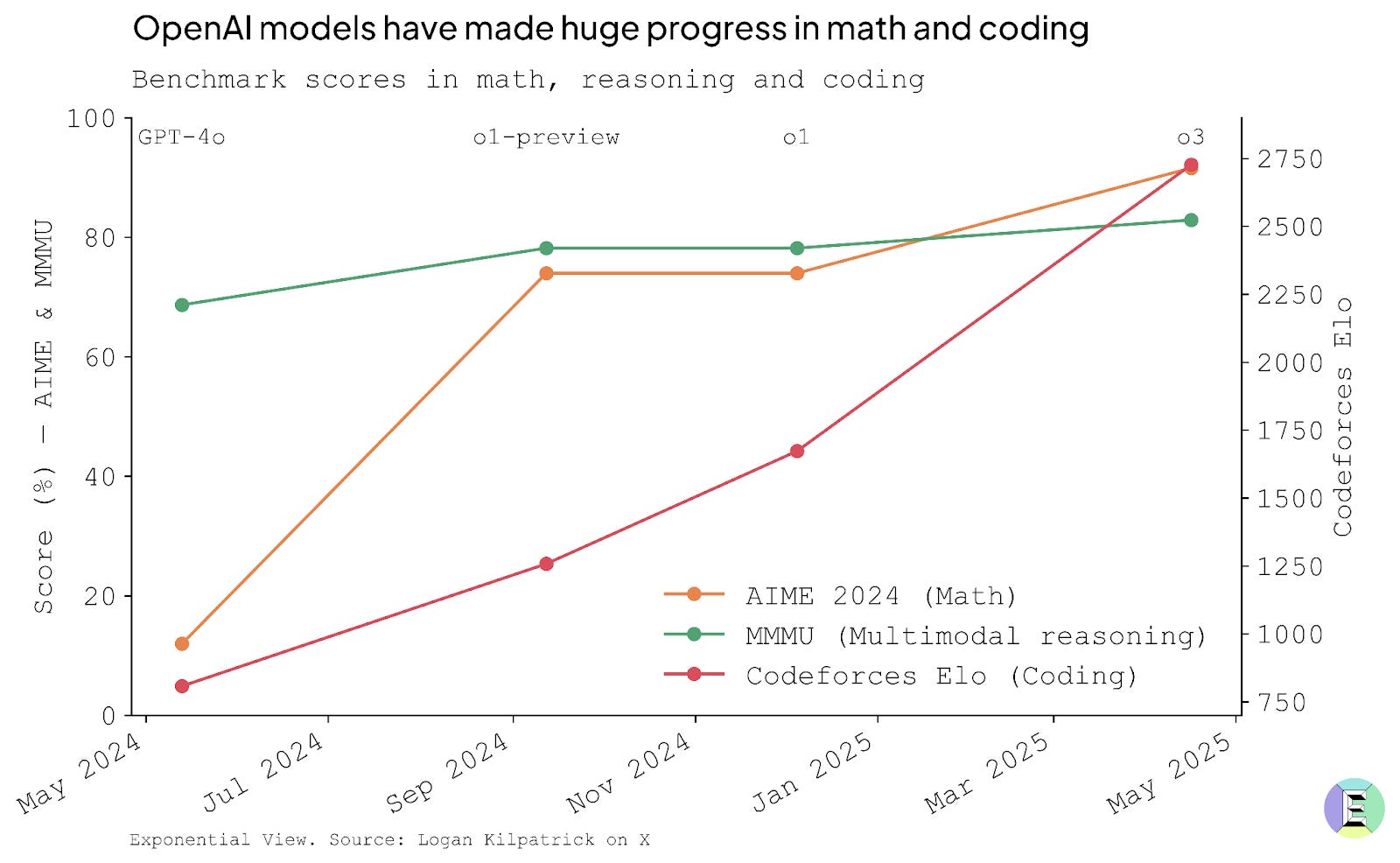
Personal experience underscores this vividly. Occasionally, I run models locally on my laptop, particularly when trapped on flights with poor Wi-Fi. These local models approximate the capabilities of GPT-4 roughly a year ago—lacking the reasoning and tool-use features we have witnessed since. Using these models offline now feels painfully limited compared with the current state of the art.
Practical gains are clear, especially in real-world workflows. In software engineering, AI-powered coding tools have swiftly evolved from basic code hints to managing entire processes—planning, writing, testing and submitting finished work for human review. Systems such as Claude Code and OpenAI’s Codex now automate these tasks end-to-end, reducing humans to supervisory roles. Though not flawless, their rapid improvement streamlines workflows by converting tedious coding into manageable reviews.
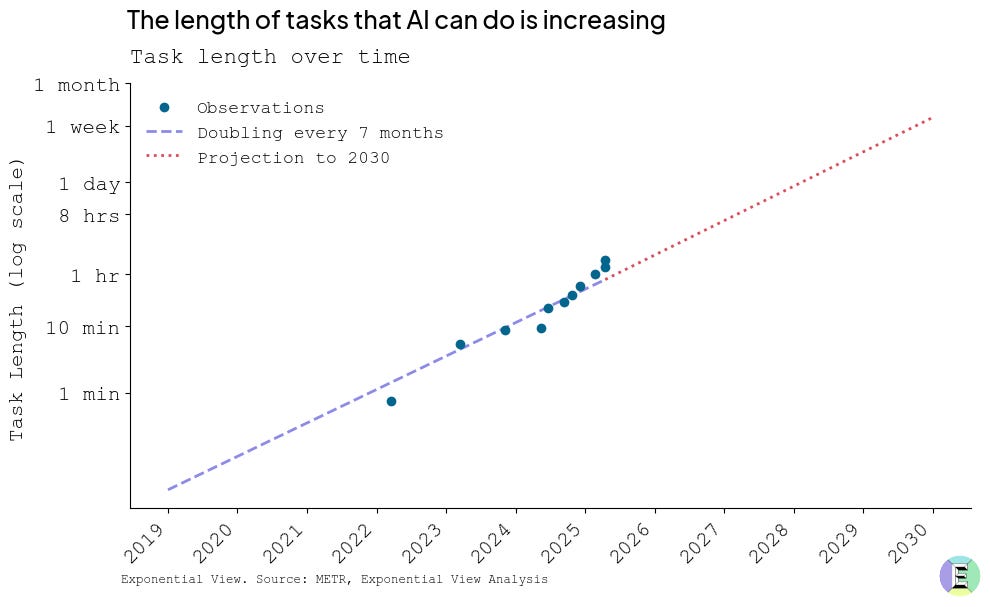
These advancements are possible because models can now handle increasingly complex tasks. Consider METR’s latest agent-endurance benchmark, which measures how long AI models can sustain intricate multistep workflows. On this test, top-performing models last three to five times longer than they did only six months ago. This dramatic improvement signals deeper planning capabilities and more reliable tool use.
In short, the capability curve remains steep—and it continues to climb rapidly across multiple dimensions.
Perhaps even more crucially, the unit costs of AI are plunging exponentially. This is central to my definition of exponential technology—not solely about improving performance but about rapidly collapsing costs for a given capability.
Consider ChatGPT’s inference prices, which have roughly halved every six months—outpacing even the historical cost declines in DRAM and solar power. This steep drop stems from relentless algorithmic improvements and fierce competition among providers. Lower prices in turn drive wider adoption: the cheaper an AI agent becomes, the more extensively it can be deployed. (Though clearly there is still room for improvement—I recently burned through $80 of Replit credits in a single evening.)
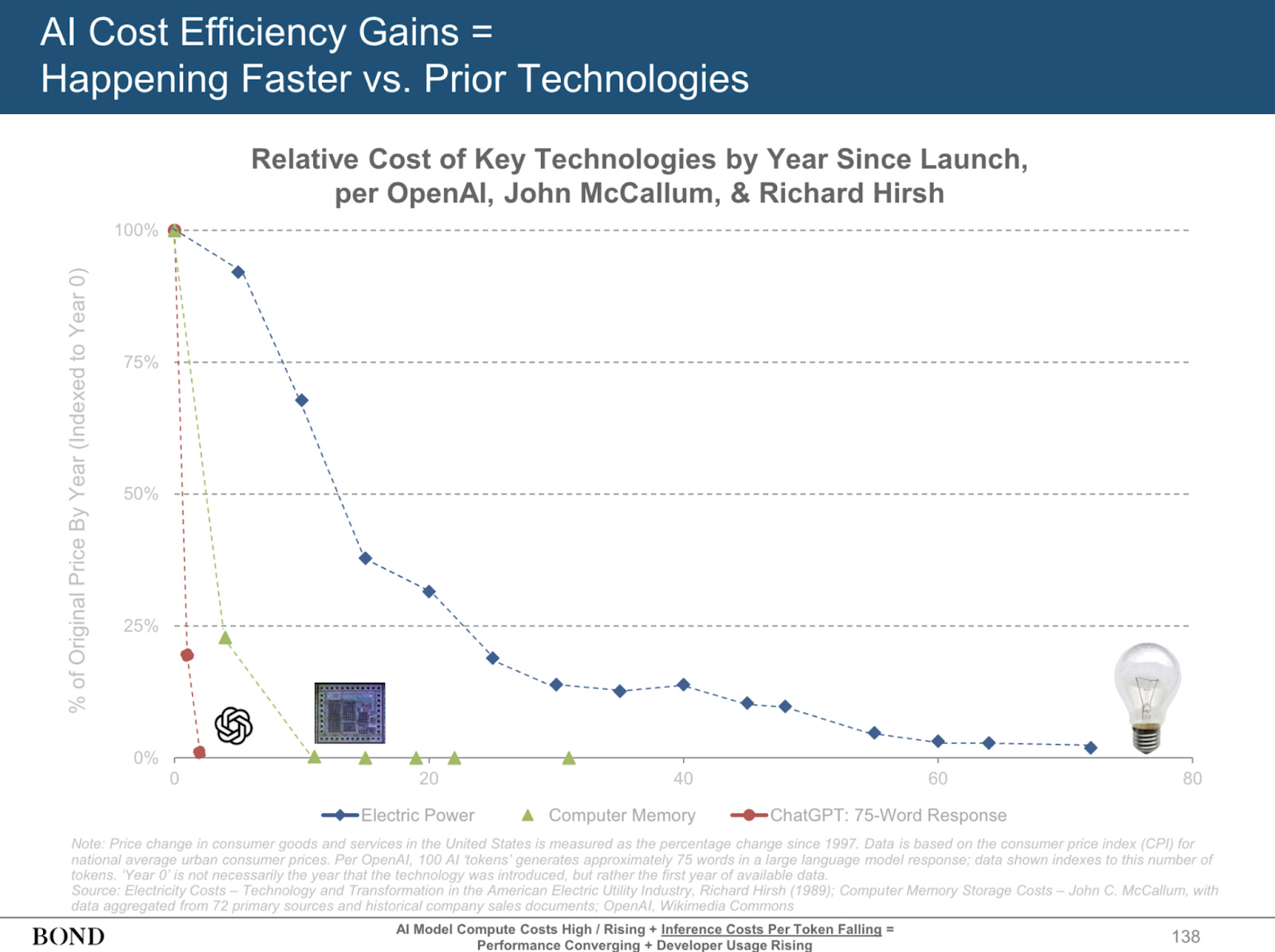
Importantly, even if AI labs suddenly stopped frontier research and model scaling overnight, these cost improvements would continue accumulating. In my back-room conversations, experts are roughly split 50/50 on whether scaling laws alone can carry us all the way to AGI—whatever that ultimately entails. If scaling alone is not sufficient, most believe we might still be only one or two significant conceptual breakthroughs away.
Yet debates about scaling do not fundamentally change the core argument. Future capability enhancements, while valuable, are additive—not prerequisites—for substantial economic transformation. Existing models already surpass what most enterprises can effectively absorb or leverage. At Exponential View, we are still figuring out how to redefine our workflows around o3; I expect most organizations are still navigating how to integrate GPT-4o fully.
McKinsey reports that nearly every company is investing in AI, yet only 1% claim they have fully integrated it into workflows and achieved meaningful business outcomes. And honestly, even that 1% is probably just PR.
Why absorption lags – the three frictions
This sluggish absorption, rather than frontier innovation, is the main reason we can see the AI boom everywhere except in the economic statistics. That remains true even as AI startups rack up millions to tens of billions in revenue at record speed. But the global economy is huge—about $100 trillion a year—so that is a lot of OpenAIs. It will take several years, not a few quarters, before even the fastest-growing AI startups contribute one percent to global income. (Incidentally, I have little doubt they will, and that AI-native newcomers will replace many incumbents across industries over the next two decades, just not in the next two years.)
The rest of the economy is dominated by incumbents. Those incumbents are laced with friction. They need to tackle it. Three distinct institutional frictions underpin this capability-absorption gap, and each one is structural rather than technological.
